 k8s网络概述-容器网络
k8s网络概述-容器网络
# 一、节点网络
节点网络,"物理可达"及节点之间可互相通信,主要承载集群pod和节点网络流量,节点网络一般都是在集群创建之前已经确定;对CNI插件选型有影响。
# 二、容器网络
容器网络,pod在相同node上可达,pod跨node节点可达,pod网络由CNI插件创建及维护。
- 同一个pod,有多个容器时,多个容器处于同一个网络命名空间,使用回环地址通信。
- 同一个节点间pod,通过虚拟网卡对
veth,一端连接宿主机虚拟网卡,一端连接pod,属于2层通信。 - 不同节点间pod,通过隧道网络。
# 三、集群网络
集群网络,提供集群服务svc到pod的动态映射,提供负载均衡,服务发现。

# 四、CNI
# 4.1 pod网络 创建过程
Kubelet --> CRI --> CNI --> 读取网络插件配置 --> 执行网络插件二进制文件
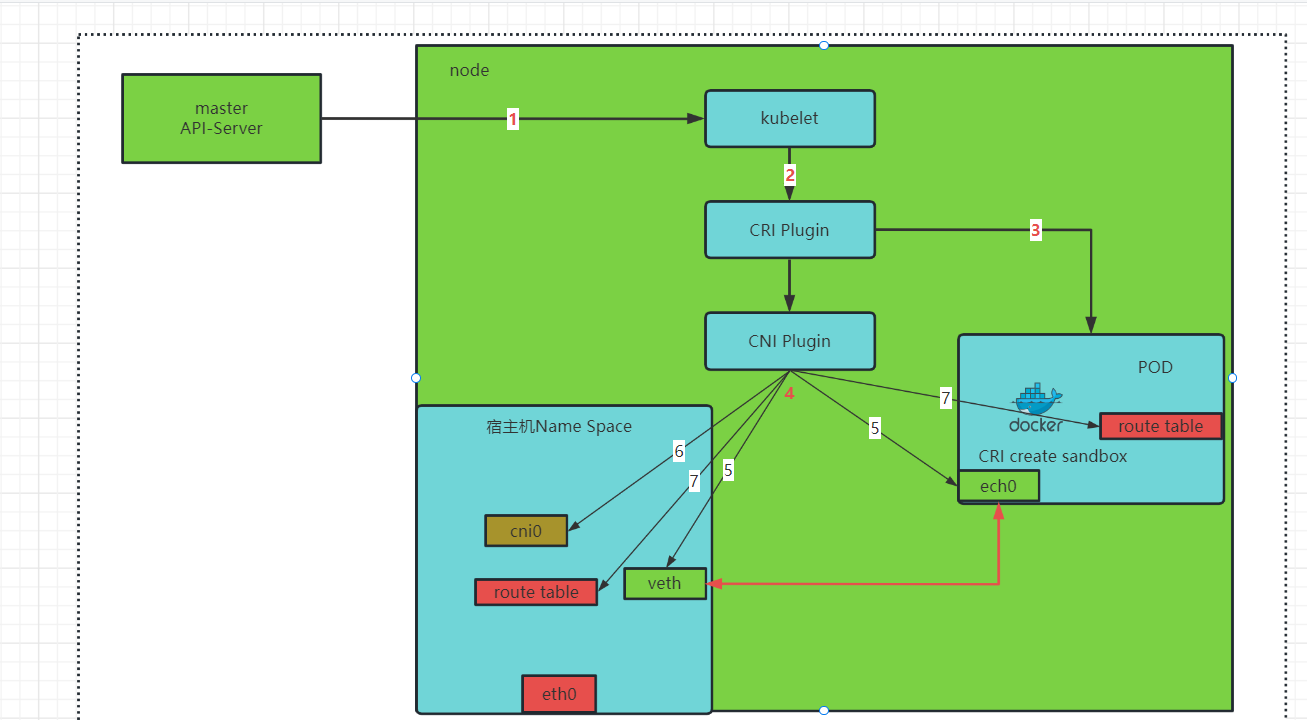
- 1、API Server根据调度算法,选定一个node节点,把信息通知到该节点kubelet,pod创建由kubelet接管。
- 2、kubelet调用CRI(容器运行时接口)创建pod,完成pod中容器的一系列资源创建。
- 3、CRI会创建pod的namespace(IPC NS、Net NS、IPD NS),其实就是创建
pause容器,针对于同一个pod中的容器,共享pause命名空间资源。 - 4、CRI调用CNI接口调用具体的CNI插件(插件可执行文件),CNI 插件为容器创建网络(具体就是图中5、6、7)。
- 5、虚拟以太网对,一端连接pod,命名为ech0,并为其设置IP,一端连接宿主机虚拟网卡cni0,命名veth*。
- 6、在宿主机创建虚拟网桥cni0
- 7、设置pod及宿主机路由表
# 4.2 calico
在了解calico网络插件之前,我们先来熟悉下BGP几个概念。
什么是BGP
BGP是运行于 TCP上的一种自治系统的路由协议,也是互联网上一个核心的去中心化自治路由协议。网络可达信息包括列出的自治系统(AS)的信息。这些信息有效地构造了 AS 互联的拓朴图并由此清除了路由环路,同时在 AS 级别上可实施策略决策。在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位。
BGP图解
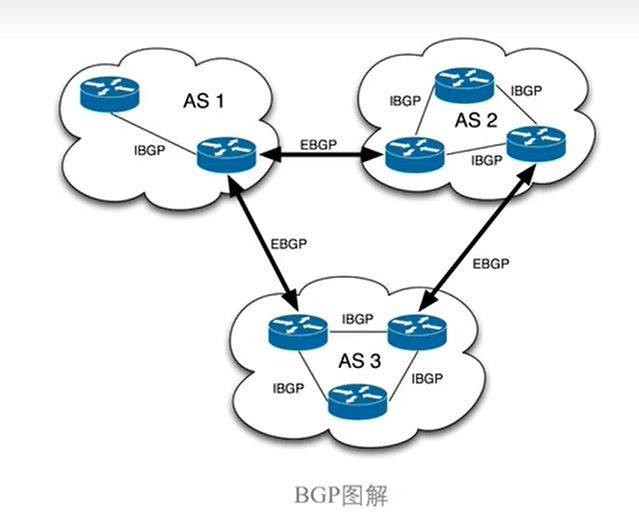
AS:是 指一个自治系统,其内部也可能运行其他路由协议(OSPF,RIP等),每一个自治系统都为分配一个唯一的AS号。
BGP Speaker: 全网互联,就是一个BGP Speaker需要与其它所有的BGP Speaker建立bgp连接(形成一个bgp mesh),
RR:路由反射器,能够收集所有Client发送的信息然后向其他指定Client传递,类似于一个信息集中收发站,并把学到的其它AS路由信息发送至内部AS。
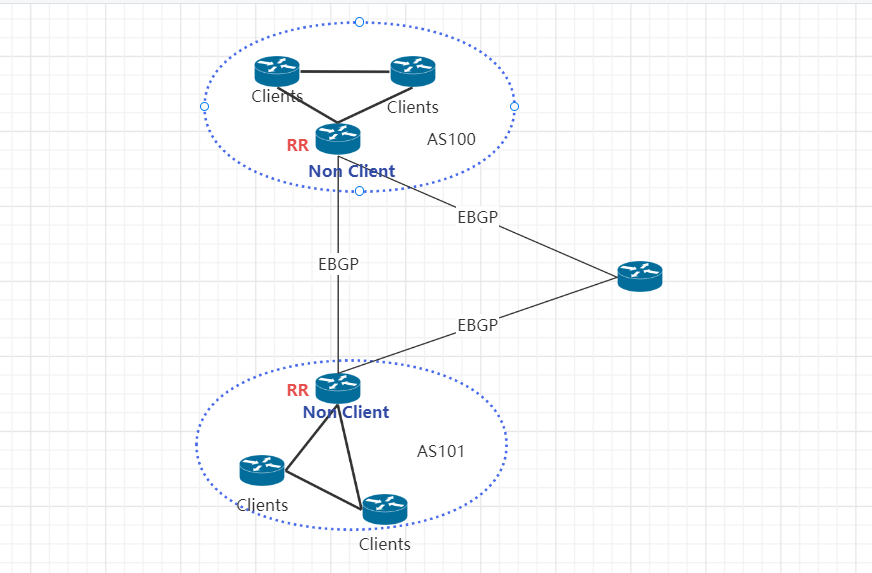
大型网络仅仅使用 BGP client 形成 mesh 全网互联(BGP Speaker)的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,采用BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数
Router Reflector图解
# 4.2.1 Calico介绍
Calico工作原理
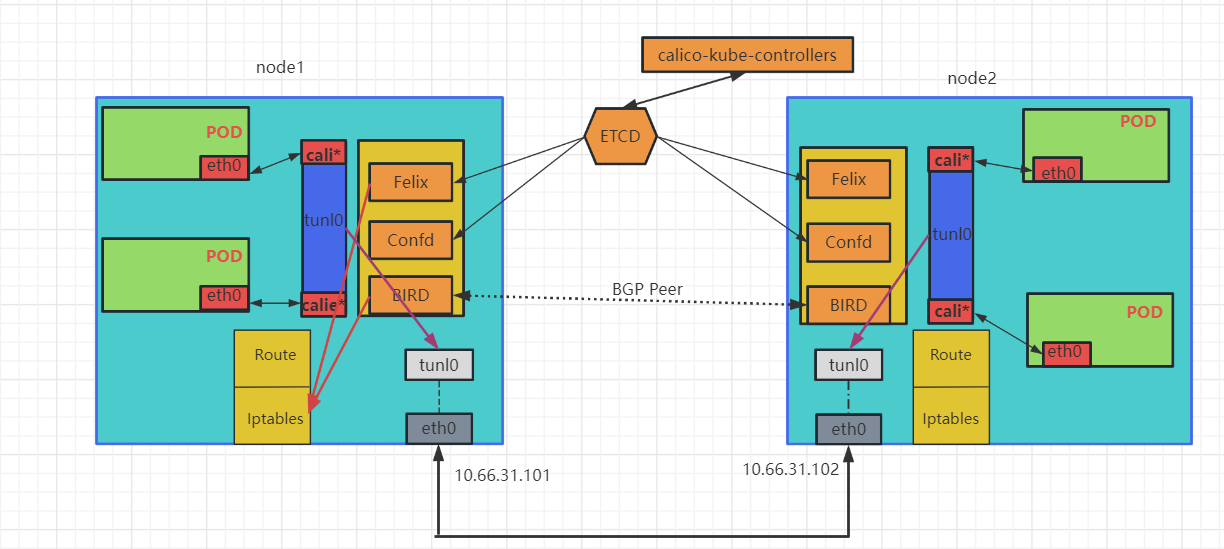
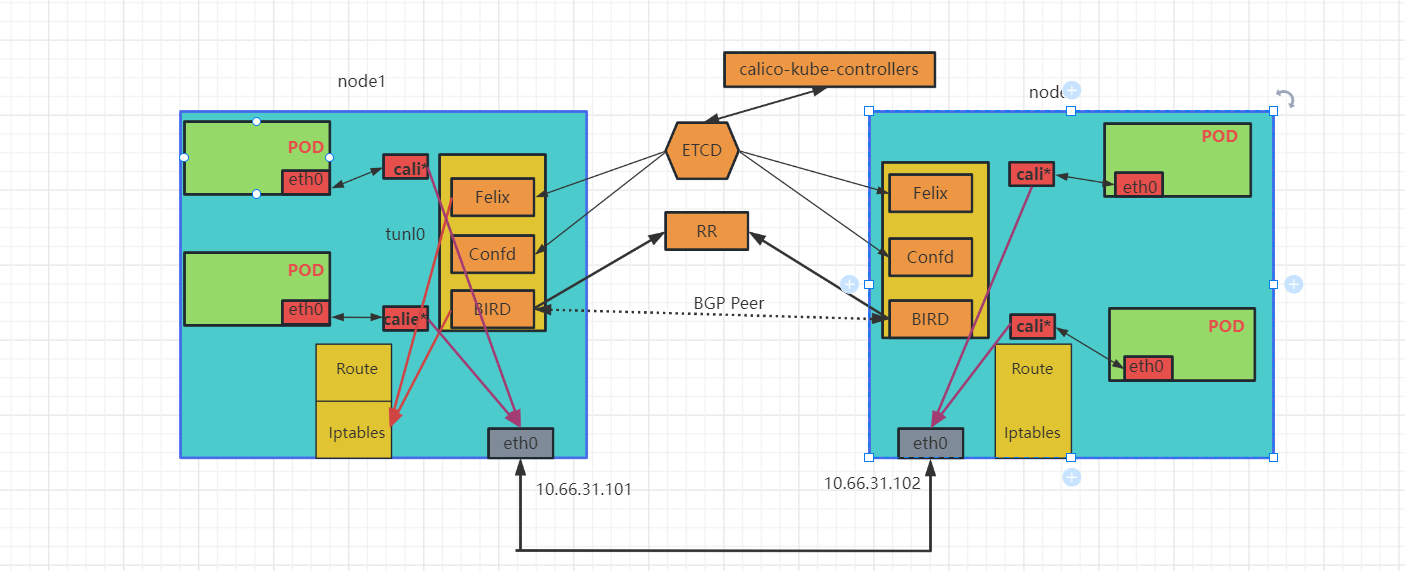
Calico是一个纯三层的协议,Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心。
Calico网络模型主要工作组件:
- calico-kube-controllers:通过与kube-apiserver交互,负责把k8s集群各种变化同步更新到calico网络中,同时也为
calicoctl命令执行提供依据。
- Felix: calico的核心组件,运行在每个节点的agent进程,主要负责网络接口的管理和监听、路由表信息、ARP管理、ACl管理和同步、状态上报等。
- ETCD: 负责网络元数据的存储,保证整个集群中数据一致性。
- BIRD: 作为一个BGP客户端,负责把Felix写入到系统内核的路由信息通过
BGP Peer分发到当前Calico网络集群中。 - Confd: 监听etcd以了解BGP配置和全局默认值的更改。根据ETCD中数据的更新,可以动态生成BIRD配置文件。当配置文件更改时,confd触发BIRD重新加载新文件。
Calico BGP网络工作模式概念:
- 全网状连接(Full-mesh): 启用 BGP 后,Calico 的默认行为是创建内部 BGP (iBGP) 连接的全网状连接,其中每个节点相互对等。这允许 Calico 在任何 L2 网络上运行,无论是公共云还是私有云,或者是配置 (opens new window)了基于IPIP的overlays网络。Calico 不将 BGP 用于 VXLAN overlays网络。全网状结构非常适合 100 个或更少节点的中小型部署,但在规模明显更大的情况下,全网状结构的效率会降低,calico建议使用路由反射器(Route reflectors)。
- 路由反射器(Route reflectors):要构建大型内部 BGP (iBGP) 集群,可以使用BGP 路由反射器来减少每个节点上使用的 BGP 对等体的数量。在这个模型中,一些节点充当路由反射器,并被配置为在它们之间建立一个完整的网格。然后将其他节点配置为与这些路由反射器的子集对等(通常为 2 个用于冗余),与全网状相比减少了 BGP 对等连接的总数。
# 4.2.2 Calico网络模式
- IPIP网络
IPIP模式下,calico会使用tunl0隧道设备(基于IP层的网桥),ip会现先经过tunl0,tunl0设备会将IP包封装为宿主机IP包,然后再由宿主机进行转发。
- BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
说明
Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter(虚拟路由)来负责数据转发,它会为每个容器分配一个ip,每个节点都是路由,把不同host的容器连接起来,从而实现跨主机间容器通信。而每个vRouter通过BGP协议(边界网关协议)负责把自己节点的路由信息向整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGProute reflector来完成;Calico基于iptables还提供了丰富而灵活的网络策略,保证通过各个节点上的ACLs来提供多租户隔离、安全组以及其他可达性限制等功能。
# 4.2.3 IPIP模式数据包分析
- 启动两个pod

- 登录
node01节点所属pod,ping 172.41.58.207
[root@k8s-master01 ~]# kubectl exec -it busybox-7dcdb7fd4b-m8qj9 -- sh
/ #
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if24: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue
link/ether 0e:ce:10:0c:47:05 brd ff:ff:ff:ff:ff:ff
inet 172.41.85.208/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::cce:10ff:fe0c:4705/64 scope link
valid_lft forever preferred_lft forever
/ # ping 172.41.58.207
PING 172.41.58.207 (172.41.58.207): 56 data bytes
64 bytes from 172.41.58.207: seq=0 ttl=62 time=0.797 ms
64 bytes from 172.41.58.207: seq=1 ttl=62 time=0.631 ms
64 bytes from 172.41.58.207: seq=2 ttl=62 time=2.018 ms
64 bytes from 172.41.58.207: seq=3 ttl=62 time=0.426 m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
查看node01组主机路由信息
[root@k8s-node01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.66.31.254 0.0.0.0 UG 100 0 0 ens192
10.66.31.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
172.41.32.128 10.66.31.100 255.255.255.192 UG 0 0 0 tunl0
172.41.58.192 10.66.31.102 255.255.255.192 UG 0 0 0 tunl0
172.41.85.192 0.0.0.0 255.255.255.192 U 0 0 0 *
172.41.85.193 0.0.0.0 255.255.255.255 UH 0 0 0 calie112be7fa8a
172.41.85.194 0.0.0.0 255.255.255.255 UH 0 0 0 calif7d82fd9d93
172.41.85.195 0.0.0.0 255.255.255.255 UH 0 0 0 cali2f1b70473d0
172.41.85.196 0.0.0.0 255.255.255.255 UH 0 0 0 cali5e68b685b3f
172.41.85.199 0.0.0.0 255.255.255.255 UH 0 0 0 cali1abad8afd57
172.41.85.200 0.0.0.0 255.255.255.255 UH 0 0 0 cali10500ca9e63
172.41.85.208 0.0.0.0 255.255.255.255 UH 0 0 0 calif78690f679c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
说明
我们进入容器busybox-7dcdb7fd4b-m8qj9,查看容器的路由可以看到,去往任意网段的路由,都会发往默认网关169.254.1.1;
在容器所在宿主机node01,查看宿主机路由信息, 可以看到有一条路由172.41.58.192,该条路由意思就是去往172.41.58.192/26网段的路由数据包直接发送到网关10.66.31.102,该网关其实就是node02节点IP。
- 登录
node02查看宿主机路由信息
[root@k8s-node02 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.66.31.254 0.0.0.0 UG 100 0 0 ens192
10.66.31.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
172.41.32.128 10.66.31.100 255.255.255.192 UG 0 0 0 tunl0
172.41.58.192 0.0.0.0 255.255.255.192 U 0 0 0 *
172.41.58.193 0.0.0.0 255.255.255.255 UH 0 0 0 cali9ae4c684228
172.41.58.194 0.0.0.0 255.255.255.255 UH 0 0 0 calibd6e420f0d1
172.41.58.195 0.0.0.0 255.255.255.255 UH 0 0 0 cali097a6b077a1
172.41.58.199 0.0.0.0 255.255.255.255 UH 0 0 0 calid75abf4f5e0
172.41.58.200 0.0.0.0 255.255.255.255 UH 0 0 0 calica626582d94
172.41.58.206 0.0.0.0 255.255.255.255 UH 0 0 0 cali11239f98883
172.41.58.207 0.0.0.0 255.255.255.255 UH 0 0 0 calie46f5d5942e
172.41.85.192 10.66.31.101 255.255.255.192 UG 0 0 0 tunl0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
说明
可以看到宿主机有一条路由172.41.58.207,该条路由是本机直连路由,数据包直接丢给对应网卡接口calie46f5d5942e,calie46f5d5942e其实就是pod虚拟网卡对的其中一端。
- 总结
通过上面宿主机及容器路由信息我们可看出来,所有跨节点的通信,路由都是经过tunl0进行转发。
# 4.2.4 BGP模式数据包分析
calico默认部署模式为IPIP,如果想要使用BGP模式,则需要修改配置,进行部署。
- 修改配置
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP 修改为Never即可
- name: CALICO_IPV4POOL_IPIP
value: "Never"
2
3
4
5
6
7
8
9
- 这里我们同样启动2个pod进行验证

- 分析
node01节点容器路由
[root@k8s-master01 ~]# kubectl exec -it busybox-7dcdb7fd4b-d9hm2 -- sh
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 36:bd:2f:01:e4:3a brd ff:ff:ff:ff:ff:ff
inet 172.41.85.198/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::34bd:2fff:fe01:e43a/64 scope link
valid_lft forever preferred_lft forever
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 登录
node01宿主机查看路由信息
[root@k8s-node01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.66.31.254 0.0.0.0 UG 100 0 0 ens192
10.66.31.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
172.41.58.192 10.66.31.102 255.255.255.192 UG 0 0 0 ens192
172.41.85.192 0.0.0.0 255.255.255.255 UH 0 0 0 cali5e68b685b3f
172.41.85.192 0.0.0.0 255.255.255.192 U 0 0 0 *
172.41.85.193 0.0.0.0 255.255.255.255 UH 0 0 0 cali10500ca9e63
172.41.85.194 0.0.0.0 255.255.255.255 UH 0 0 0 cali1abad8afd57
172.41.85.195 0.0.0.0 255.255.255.255 UH 0 0 0 calif7d82fd9d93
172.41.85.196 0.0.0.0 255.255.255.255 UH 0 0 0 cali2f1b70473d0
172.41.85.197 0.0.0.0 255.255.255.255 UH 0 0 0 calie112be7fa8a
172.41.85.198 0.0.0.0 255.255.255.255 UH 0 0 0 cali16736b92c20
2
3
4
5
6
7
8
9
10
11
12
13
14
总结
通过查看node01节点上容器路由及宿主机路由,可以看到针对于到本机的地址,直接把数据包交给虚拟网卡cali*处理,针对172.41.58.192/26网段路由,直接由宿主机ens192网卡进行转发,相对于IPIP模式数据包流转,没有再经过tunl0进行转发。
# 4.2.5 Calico IP地址管理
https://docs.tigera.io/calico/3.24/networking/ipam/migrate-pools
在日常k8s集群运维工作中,我们可能会遇到这样的场景,一般来说,开发测试生产这些环境在同一个集群中,我们如果想要把指定环境的pod分配我们提前划分好的IP网段,这样对于后面管理及网络安全策略更加方便。
4.5.1 IP地址规划
| IP池 | 环境 | 可用IP |
|---|---|---|
| 172.41.64.0/21 | prod | 2046 |
| 172.41.60.0/22 | test | 1022 |
| 172.41.56.0/22 | dev | 1022 |
| 172.41.0.0/16 | 集群 | 65534 |
4.5.2 打标签
在使用k8s集群时,我们有时候不仅要通过命名空间进行环境隔离,有时候也需要使用节点及网络进行隔离。这里为不同的node节点打标签,实现不同环境的pod在node节点隔离
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 54d v1.26.0
k8s-node01 Ready <none> 54d v1.26.0
k8s-node02 Ready <none> 54d v1.26.0
# label
[root@k8s-master01 ~]# kubectl label node k8s-node01 env=dev
node/k8s-node01 labeled
[root@k8s-master01 ~]# kubectl label node k8s-node02 env=prod
node/k8s-node02 labeled
2
3
4
5
6
7
8
9
10
11
4.5.3 删除默认地址池
# 查看默认IP地址池
[root@k8s-master01 ~]# calicoctl get ippool
NAME CIDR SELECTOR
default-ipv4-ippool 172.41.0.0/16 all()
# 删除默认地址池
[root@k8s-master01 ~]# calicoctl delete ippools default-ipv4-ippool
Successfully deleted 1 'IPPool' resource(s)
2
3
4
5
6
7
8
4.5.4 新建对应环境地址池
- DEV环境地址池
[root@k8s-master01 ip-manage]# cat ippool-dev.yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: dev-ippool
spec:
allowedUses:
- Workload
- Tunnel
cidr: 172.41.56.0/22
ipipMode: Never
natOutgoing: true
vxlanMode: Never
nodeSelector: env == "dev"
2
3
4
5
6
7
8
9
10
11
12
13
14
- PROD环境地址池
[root@k8s-master01 ip-manage]# cat ippool-prod.yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: prod-ippool
spec:
allowedUses:
- Workload
- Tunnel
cidr: 172.41.64.0/21
ipipMode: Never
natOutgoing: true
vxlanMode: Never
nodeSelector: env == "prod"
2
3
4
5
6
7
8
9
10
11
12
13
14
- 创建
[root@k8s-master01 ip-manage]# calicoctl create -f ippool-dev.yaml
Successfully created 1 'IPPool' resource(s)
[root@k8s-master01 ip-manage]# calicoctl create -f ippool-prod.yaml
Successfully created 1 'IPPool' resource(s)
[root@k8s-master01 ~]# calicoctl get ippool
NAME CIDR SELECTOR
dev-ippool 172.41.56.0/22 env == "dev"
prod-ippool 172.41.64.0/21 env == "prod"
2
3
4
5
6
7
8
4.5.5 验证IP地址池
可以看到对应的pod调度到指定节点后,IP分配符合预期

总结
注意
修改pod地址池大多不会影响现有pod,对于现有pod基于deployment运行,只需要删除pod重建即可重新分配IP,但是为了集群文档,建议IP地址池的分配,在集群搭建前就完成。
# 4.2.6 BGP RR模式
默认情况下,Calico网络节点直接全互联,节点数量增加将导致连接数剧增、资源占用剧增,针对于50节点及以下,可采用用该模式,当集群节点大于50时,建议开启RR模式。
注意: <mark>关闭全互联时会导致网络暂时中断</mark>
4.2.6.1 查看当前节点BGP连接

4.2.6.2 创建默认BGPConfiguration
[root@k8s-master01 ip-manage]# cat bgpconfiguration.yaml
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false # 关闭全网互联模式
asNumber: 64512
# 应用
[root@k8s-master01 ip-manage]# calicoctl apply -f bgpconfiguration.yaml
Successfully applied 1 'BGPConfiguration' resource(s)
[root@k8s-master01 ip-manage]# calicoctl get bgpconfiguration
NAME LOGSEVERITY MESHENABLED ASNUMBER
default Info false 64512
2
3
4
5
6
7
8
9
10
11
12
13
14
15
4.2.6.3 选定节点配置路由反射器(Route Reflectors)
这里选择k8s-master01,k8s-node01节点作为路由反射器,修改节点信息,新增
routeReflectorClusterID配置
# 查看集群节点信息
[root@k8s-master01 ~]# calicoctl get nodes -owide
NAME ASN IPV4 IPV6
k8s-master01 (63400) 10.66.31.100/24
k8s-node01 (63400) 10.66.31.101/24
k8s-node02 (63400) 10.66.31.102/24
k8s-node03 (63400) 10.66.31.131/24
# 给选定为rr节点新增标签
[root@k8s-master01 ~]# kubectl label node k8s-master01 router-reflector=true
[root@k8s-master01 ~]# kubectl label node k8s-node01 router-reflector=true
# 导出master、node01节点配置 修改后应用
[root@k8s-master01 ~]# calicoctl get node k8s-master01 -o yaml --export > /opt/data/ip-manage/k8s-master01.yaml
[root@k8s-master01 ~]# calicoctl get node k8s-node01 -o yaml --export > /opt/data/ip-manage/k8s-node01.yaml
[root@k8s-master01 ~]# cat /opt/data/ip-manage/k8s-master01.yaml
apiVersion: projectcalico.org/v3
kind: Node
metadata:
annotations:
projectcalico.org/kube-labels: '{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"k8s-master01","kubernetes.io/os":"linux","node-role.kubernetes.io/control-plane":"","node.kubernetes.io/exclude-from-external-load-balancers":"","router-reflector":"true"}'
creationTimestamp: "2023-01-04T09:12:07Z"
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: k8s-master01
kubernetes.io/os: linux
node-role.kubernetes.io/control-plane: ""
node.kubernetes.io/exclude-from-external-load-balancers: ""
router-reflector: "true"
name: k8s-master01
resourceVersion: "7751485"
uid: 2bf182b2-caf2-4414-9a06-48648b1b483a
spec:
addresses:
- address: 10.66.31.100/24
type: CalicoNodeIP
- address: 10.66.31.100
type: InternalIP
bgp:
ipv4Address: 10.66.31.100/24
routeReflectorClusterID: 10.244.0.1 # 多个路由反射器是高可用的他们的集群id应该一致
orchRefs:
- nodeName: k8s-master01
orchestrator: k8s
status:
podCIDRs:
- 172.41.0.0/24
[root@k8s-master01 ip-manage]# cat k8s-node01.yaml
apiVersion: projectcalico.org/v3
kind: Node
metadata:
annotations:
projectcalico.org/kube-labels: '{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","env":"dev","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"k8s-node01","kubernetes.io/os":"linux","router-reflector":"true"}'
creationTimestamp: null
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
env: dev
kubernetes.io/arch: amd64
kubernetes.io/hostname: k8s-node01
kubernetes.io/os: linux
router-reflector: "true"
name: k8s-node01
spec:
addresses:
- address: 10.66.31.101/24
type: CalicoNodeIP
- address: 10.66.31.101
type: InternalIP
bgp:
ipv4Address: 10.66.31.101/24
routeReflectorClusterID: 10.244.0.1
orchRefs:
- nodeName: k8s-node01
orchestrator: k8s
status:
podCIDRs:
- 172.41.1.0/24
# 更新k8s-master01、k8s-node01节点信息
[root@k8s-master01 ip-manage]# calicoctl apply -f k8s-master01.yaml
[root@k8s-master01 ip-manage]# calicoctl apply -f k8s-node01.yaml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
4.2.6.4 添加BGP Peer
- rr节点之间互联
[root@k8s-master01 ip-manage]# cat rr-peer.yaml
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: peer-to-rrs
spec:
nodeSelector: has(router-reflector) # rr节点之间
peerSelector: rhas(router-reflector) # 选择route-reflector=true的标签k8节点作为rr节点,下发路由信息
# 应用bgp
[root@k8s-master01 ip-manage]# calicoctl apply -f rr-peer.yaml
Successfully applied 1 'BGPPeer' resource(s)
2
3
4
5
6
7
8
9
10
11
12
- rr与普通node节点互联
[root@k8s-master01 ip-manage]# cat rr-node-peer.yaml
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: peer-to-rr-node
spec:
nodeSelector: "!has(router-reflector)"
peerSelector: has(router-reflector)
# 应用bgp
[root@k8s-master01 ip-manage]# calicoctl apply -f rr-node-peer.yaml
Successfully applied 1 'BGPPeer' resource(s)
2
3
4
5
6
7
8
9
10
11
4.2.6.5 查看当前节点间连接
rr节点与所有节点互联,非路由反射节点只与rr节点互联
- 路由反射节点
k8s-master01,k8s-node01
[root@k8s-master01 ip-manage]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.66.31.101 | node specific | up | 10:29:41 | Established |
| 10.66.31.102 | node specific | up | 01:25:36 | Established |
| 10.66.31.131 | node specific | up | 01:25:35 | Established |
+--------------+---------------+-------+----------+-------------+
[root@k8s-node01 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.66.31.100 | node specific | up | 10:29:41 | Established |
| 10.66.31.102 | node specific | up | 01:25:36 | Established |
| 10.66.31.131 | node specific | up | 01:25:38 | Established |
+--------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 非路由反射节点
[root@k8s-node03 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.66.31.100 | node specific | up | 01:25:36 | Established |
| 10.66.31.101 | node specific | up | 01:25:38 | Established |
+--------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
2
3
4
5
6
7
8
9
10
11
12
13
# 4.2.7 Calico网络BGP拓扑
- 全局互联(node-to-node mesh)
全互联模式,就是集群节点之间互相建立bgp连接,网络中bgp总连接数是按照O(n^2)增长的,有太多的BGP Speaker时,会消耗大量的连接,这也是Calico默认的互联模式。
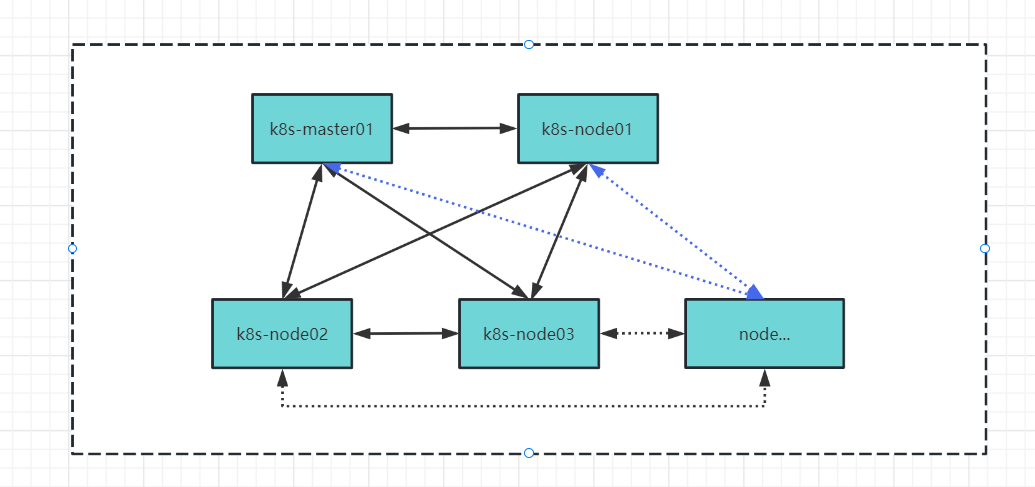
- Global Peer(本文演示)
指在网络中指定一个或多个BGP Speaker作为Router Reflection,RR与所有的BGP Speaker建立BGP连接,如果有多个RR,则rr之间也需要互联,一般这种情况多个RR是用于冗余。
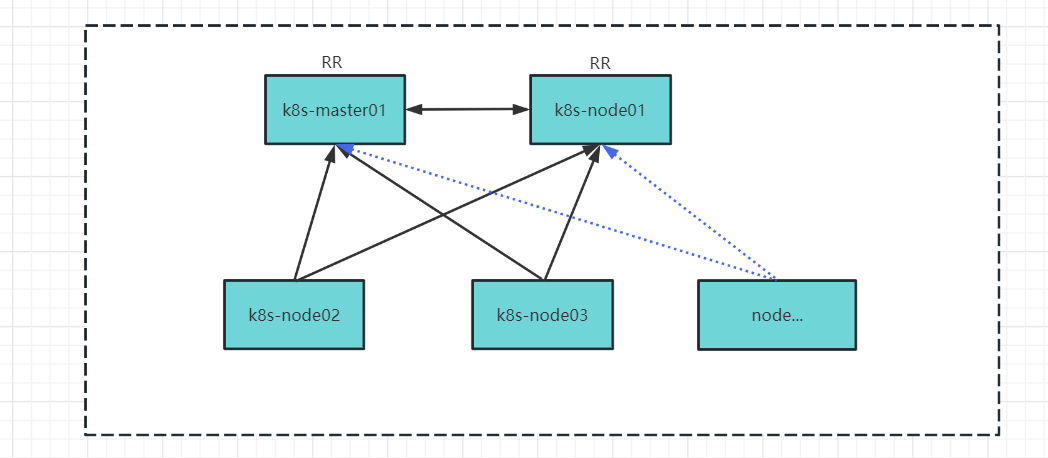
- node Peer
node Peer就是手动创建的BGP Speaker,只有指定的node会与其建立连接,这种场景一般是用于机器分区域,比如不同的机柜,每一个机柜选出一个RR,然后下面的节点与该RR互联,不同机柜之间的RR在互联。
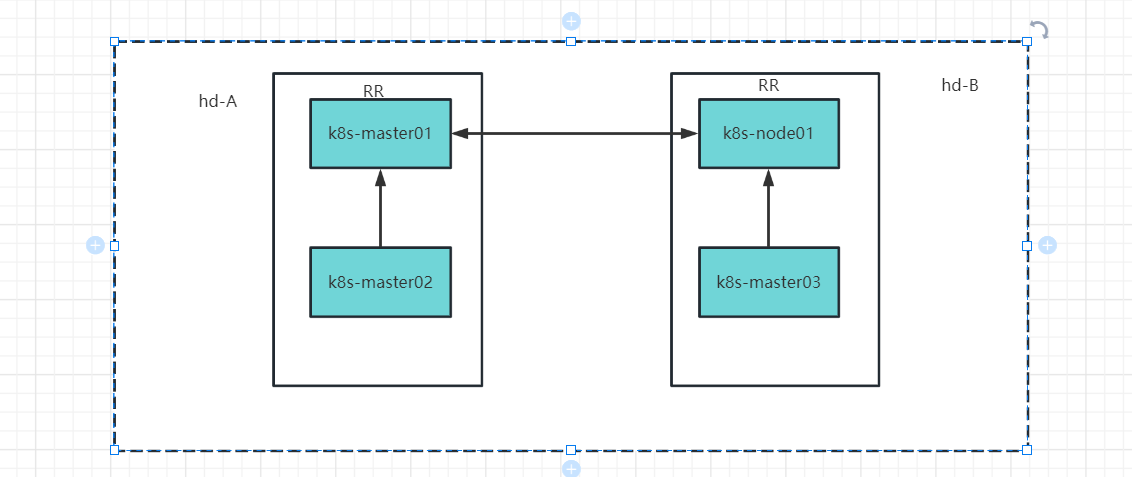
该模式配置步骤
# AS号划分
# ## hd-A AS:63400 节点标签:area=hd-a rr节点同时需要calico-role=hd-a-rr
# ## hd-B AS:63401 节点标签:area=hd-b rr节点同时需要标签calico-role=hd-b-rr
# BGPpeer配置
# ## hd-a机柜rr节点与node节点互联
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: hd-a-rr-node
spec:
nodeSelector: area='hd-a'
peerSelector: calico-role='hd-a-rr'
# ## hd-b机柜rr节点与node节点互联
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: hd-a-rr-node
spec:
nodeSelector: area=hd-b
peerSelector: calico-role='hd-b-rr'
# ## hd-a机柜rr节点与hd-b机柜rr节点互联
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: hd-a-rr-node
spec:
nodeSelector: calico-role='hd-a-rr'
peerSelector: calico-role='hd-b-rr'
# 导出所有node配置,按照规划把不同机柜node设置为不同的AS
# ## 同时routeReflectorClusterID对于同一个AS下的节点该ID需要保持一致
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 4.3 flannel
# 4.3.1 flannel介绍
Flannel也是k8s网络CNI常用的一种实现方式,是一种Overlay 跨主机容器网络解决方案。
# 4.3.2 通信原理
Flannel会在集群中每一个节点部署一个agent(flannel代理),该代理为宿主机从定义的pod网段中申请一个子网,当节点启动一个容器的时候,会从该子网中获取一个ip地址,每一个主机子网都不一样。
节点子网查看
[root@k8s-node01 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=172.14.0.0/16
FLANNEL_SUBNET=172.14.1.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
2
3
4
5
# 4.3.3 工作模式 虚拟隧道短点IP地址
目前Flannel支持三种工作模式:
- UDP:使用设备 flannel.0 进行封包解包,不是内核原生支持,频繁地内核态用户态切换,性能非常差,官方已经不推荐使用该模式;
- VxLAN: 使用flannel.1进行封包解包,内核原生支持,性能较强。
- host-gw:无需flannel.1这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强
# 4.3.4 VxLAN
VxLAN,是Linux本身支持的一种网络虚拟化技术,VXLAN可以完全在内核态实现封装和解封装工作,通过"隧道"机制,构建出覆盖网络(Overlay Network)。
- VxLAN模式通信
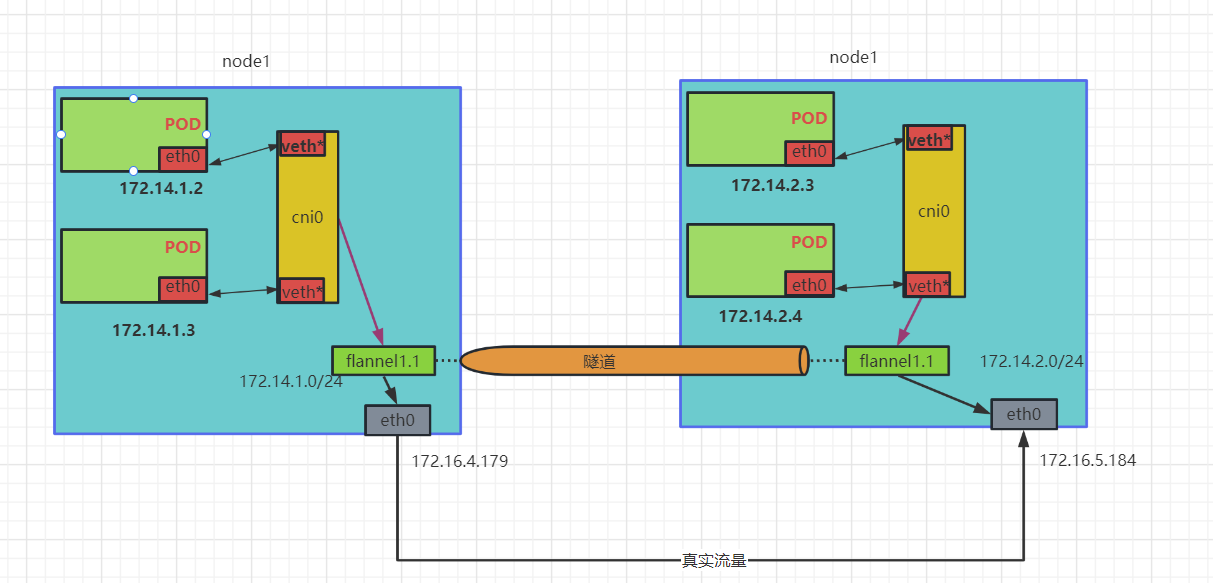
说明
- cni0: 当节点启动容器时,会检查当前节点是否有cni0虚拟网卡,如果没有则会自动创建,对于同节点pod,都是通过该虚拟网卡通信。
- ech0<-->veth*:虚拟
以太网卡对,一端连接pod,一端连接cni0。 - flannel1.1:虚拟隧道端点(VTEP)。
为了探究VxLAN通信机制,这里启动2个POD。
[root@k8s-master01 ~]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7695fcb5b5-ljlkr 1/1 Running 0 3m29s 172.14.2.2 k8s-node02 <none> <none>
nginx-deployment-7695fcb5b5-mjgnw 1/1 Running 0 3m 172.14.1.4 k8s-node01 <none> <none>
2
3
4
- 查看node1、node2节点路由表信息
[root@k8s-node01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.4.253 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.14.0.0 172.14.0.0 255.255.255.0 UG 0 0 0 flannel.1
172.14.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.14.2.0 172.14.2.0 255.255.255.0 UG 0 0 0 flannel.1
172.16.4.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
[root@k8s-node02 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.5.253 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.14.0.0 172.14.0.0 255.255.255.0 UG 0 0 0 flannel.1
172.14.1.0 172.14.1.0 255.255.255.0 UG 0 0 0 flannel.1
172.14.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.16.5.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
说明
当pod跨节点通信时,例如,pod1(172.14.1.4)访问pod2(172.14.2.2),根据pod本身路由表信息,先把数据包发送给cni0,cni0再把数据包发送给本机的flannel1.1,这时本机的flannel程序会使用VxLAN协议封装该数据包,然后通过api-server查询目的IP路由信息,最后通过UDP协议(默认8472端口),把数据包传输到目的主机上,目的主机接收到数据包后,会反向操作一遍,本机的flannel程序进行解包操作,然后转发给本机 flannel1.1,然后转给cni0,最终找到对应的pod。
上面只是简单描述了数据包的流转,其实如果通过抓包分析,可以看到最终还是需要借助宿主机的网卡进行通信
# 4.3.5 host-GW
host-gw是一种纯三层网络的方案,性能最高,即 Node 节点把自己的网络接口当做 pod 的网关使用,从而使不同节点上的 node 进行通信,这个性能比 VxLAN 高,因为它没有额外开销。这个比较类似Calico的BGP模式,不过也是一样,对节点网络有要求,需要二层可达。
::: tip注意
因为目前大多都是使用的云环境,云主机目前的vpc属于SDN网络,使用host-GW就算是在同一个网段也是无法通信的,因此这里不在演示。
:::
# 4.4 terway(该模式暂未实现)
Terway (opens new window)是阿里云开源的基于VPC网络的CNI插件,支持VPC和ENI模式,对于使用云服务器来搭建k8s集群,可以直接使用该网络插件,可以很好的与vpc网络结合。
4.4.1 创建子账号
子账号主要是用于授权可以操作vpc网络,这里不再一步一步演示,新建子账号后,需要创建as sk,然后授权:
{
"Version": "1",
"Statement": [{
"Action": [
"ecs:CreateNetworkInterface",
"ecs:DescribeNetworkInterfaces",
"ecs:AttachNetworkInterface",
"ecs:DetachNetworkInterface",
"ecs:DeleteNetworkInterface",
"ecs:DescribeInstanceAttribute",
"ecs:DescribeInstanceTypes",
"ecs:AssignPrivateIpAddresses",
"ecs:UnassignPrivateIpAddresses",
"ecs:DescribeInstances",
"ecs:ModifyNetworkInterfaceAttribute"
],
"Resource": [
"*"
],
"Effect": "Allow"
},
{
"Action": [
"vpc:DescribeVSwitches"
],
"Resource": [
"*"
],
"Effect": "Allow"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
4.4.2 网络规划
这里一定要先提前规划好集群使用网段,因为网段直接使用vpc子网,以便于后面维护。
| 网段 | 功能 | |
|---|---|---|
| 172.16.0.0/16 | VPC网络 | |
| 172.16.4.0/24 | 开发环境node节点 | |
| 172.16.5.0/24 | 生产环境node节点 | |
| 172.16.50.0/23 | 开发环境pod IP | |
| 172.16.52.0/22 | 生产环境pod IP |
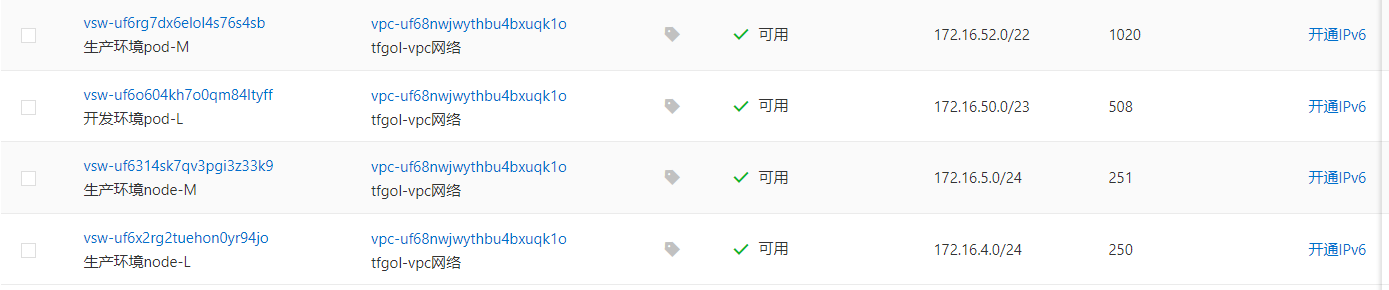
- 按照划分网段在阿里控制台创建交换机
注意
这里需要注意,交换机可用区node与pod需要对应
4.4.3 创建terway
这里选择的是ENI多IP模式,使用Aliyun ENI的辅助IP来打通网络,不受VPC的路由条目限制。
# 下载配置文件
[root@k8s-master01 ~]# wget https://raw.githubusercontent.com/AliyunContainerService/terway/main/terway-multiip.yml
# 修改配置
[root@k8s-master01 ~]# cat terway-multiip.yml
...
...
eni_conf: |
{
"version": "1",
"access_key": "上面创建的子账号ak",
"access_secret": "上面创建的子账号sk",
"service_cidr": "service 网段不能与vpc重复",
"security_group": "your 安全组id",
"max_pool_size": 5,
"min_pool_size": 0
}
....
....
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20