 k8s资源管理问题
k8s资源管理问题
# 一、节点资源
默认情况下,pod能够使用节点全部可用容量,由于集群除了运行应用级别pod资源,还有系统及集群的系统守护进程,因此需要为这些系统预留资源。
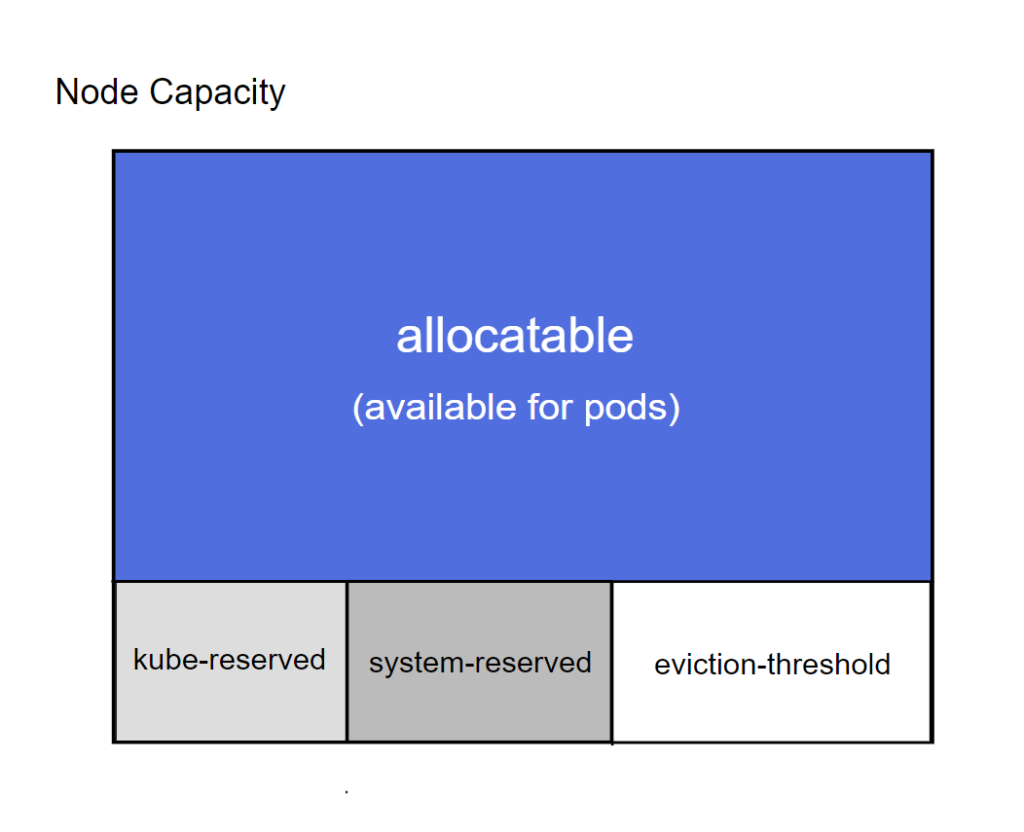
- Capacity和Allocatable
# k8s-node02 2核4G
[root@k8s-master01 ~]# kubectl describe node k8s-node02
...+
Capacity:
cpu: 2
ephemeral-storage: 38815216Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 4045376Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 35772103007
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3942976Ki
pods: 110
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
说明
- Capacity:节点资源容量
- Allocatable: 节点可分配容量,调度器申请资源时不会超过该值,目前支持CPU、memery、ephemeral-storage
- kube-reserved
kube-reserved是给kube组件预留的资源。
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
可以设置cpu、内存、存储,另外也可以指定预留一定数量的pid
- system-reserved
system-reserved是给系统守护进程,类似ssh、udev等。
--system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
- eviction-hard
eviction-hard是kubelet组件驱逐的阈值设定
# 系统可用内存小于500Mi时开始驱逐
# ## 该预留值对于pod来说 是不可用的
--eviction-hard=[memory.available<500Mi]
2
3
- Node Capacity资源管理图
# 二、驱逐机制
# 2.1 驱逐类型
驱逐类型一般有四个场景,手动驱逐、节点污点导致驱逐、pod抢占驱逐、节点压力驱逐。
# 2.1.1 手动驱逐
人为参与,使用命令进行驱逐
# 首先,驱逐node上的pod,其他节点重新创建,接着,将节点调为 SchedulingDisabled
kubectl dran k8s-node01
# cordon 停止调度 旧pod不会影响
kubectl cordon k8s-node01
2
3
4
# 2.1.2 污点驱逐
是指node节点被设置了NoExecute的污点,此时如果该节点上运行的pod没有对应的容忍度标签,则会从该节点被驱逐删除。
# 2.1.3 pod抢占驱逐
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption
Pod可以设置优先级,当资源不足时,如果有配置Pod优先级,则调度程序会尝试驱逐(抢占)优先级较低的Pod,以使完成pod的调度, 创建PriorityClass (opens new window)资源类型指定优先级值,创建pod时指定PriorityClass资源名称,以配置Pod优先级。
# 2.1.4 节点压力驱逐
节点压力驱逐,是kubelet组件根据节点资源使用情况,来执行的驱逐策略:
驱逐信号
- memory.available
- nodefs.available
- nodefs.inodesFree
- imagefs.available
- imagefs.inodesFree
- pid.available
驱逐条件
kubelet 可以指定自定义驱逐条件
软驱逐条件
- 软驱逐条件将驱逐条件与管理员所必须指定的宽限期配对。 在超过宽限期之前,kubelet 不会驱逐 Pod。 如果没有指定的宽限期,kubelet 会在启动时返回错误。
- 驱逐参数配置
eviction-soft:一组驱逐条件,如 memory.available<1.5Gi, 如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。 eviction-soft-grace-period:一组驱逐宽限期, 如 memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。 eviction-max-pod-grace-period:在满足软驱逐条件而终止 Pod 时使用的最大允许宽限期(以秒为单位)。1
2
3硬驱逐条件
- 硬驱逐条件没有宽限期。当达到硬驱逐条件时, kubelet 会立即杀死 pod,而不会正常终止以回收紧缺的资源。
memory.available<100Mi nodefs.available<10% imagefs.available<15% nodefs.inodesFree<5%(Linux 节点)1
2
3
4
监控间隔
Kubelet默认驱逐窗口期为10s。
注意
默认情况下,kubelet 轮询 cAdvisor 以定期收集内存使用情况统计信息。 如果该轮询时间窗口内内存使用量迅速增加,kubelet 可能无法足够快地观察到 MemoryPressure, 但是 OOMKiller 仍将被调用。因此有时候会看到监控上看pod资源使用率并没有达到100%,而pod已经出发OOM导致重建。

# 三、Pod回收机制与OOM killer
由于OOM killer和Kubelet的pod逐出机制的共存, 驱逐只在特定阈值内的指定间隔(默认为10秒)才开始,但OOM killer确总是保持警惕,因此,Kubelet和OOM-killer有时会表现为在某种竞争条件下为杀死行为不端的容器而出现下面的情况:在OOM killer杀掉进程后,等Kubelet来到10s窗口时,就会提示试图杀死一个不再存在的容器。
# 四、kubectl top pod显示内存使用率为100%问题
我们知道,当我们执行kubectl top pod时,有时候会看到该值会大于100%,这是因为计算时,总的内存值取的是节点Allocatable资源,这个值一般是小于主机的实际内存(给系统及集群组件预留内存资源),因此这个是符合预期的。