 GO语言学习总结系列
GO语言学习总结系列
# 一、go语言初始
1) 多核运行
2) 性能强悍(编译型语言)
2
# 1.1 go path 与 go module
- GOPATH
GOPATH 是 Go语言中使用的一个环境变量,它使用绝对路径提供项目的工作目录,在 GOPATH 指定的工作目录下,代码总是会保存在 $GOPATH/src 目录下,在工程经过 go build、go install 或 go get 等指令后,会将产生的二进制可执行文件放在 $GOPATH/bin 目录下,生成的中间缓存文件会被保存在 $GOPATH/pkg下
- GO Module
从1.11版本开始引入GO111MODULE环境变量,共有三个值:
GO111MODULE=off 关闭GOMODULE模式
GO111MODULE=on 开启GOMODULE模式,开启后,不会去GOPATH目录下查找代码
GO111MODULE=auto go命令行将会根据当前目录来决定是否启用module功能。
从1.16版本开始默认开启GO111MODULE
go module初始化命令:
"""
mkdir hello
cd hello
go mod init hello
"""
以上命令执行后,会在当前目录下生成一个go.mod文件
2
3
4
5
6
7
8
9
10
11
12
13
# 1.2 go 常用命令
go env 打印所有变量
go env -w GO111MODULE=auto 设置环境变量
go get 用于拉去外部依赖的包或者工具
go install 用于编译和安装二进制文件
go fmt 代码格式化
2
3
4
5
# 二、基础数据类型
# 2.1 标识符与关键字
// 标识符
标识符用来命名变量、类型、函数等程序实体,Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。
// 关键字
关键字是指编程语言中预先定义好的具有特殊含义的标识符,Go语言中有25个关键字.
2
3
4
5
# 2.2 变量
# 2.2.1 变量声明
var 变量名字 类型 = 表达式 // go 语言中声明变量使用var关键字
# 2.2.2 声明并赋值
var name string="tchua"
var age int=18
// 在变量声明的时候,可以直接赋值
2
3
4
# 2.2.3 声明后赋值
var name string
name = "tchua"
2
3
# 2.2.4 简短声明
name := "tchua"
a,b := 1,2
1) 可以看到这里直接写变量的值,没有指定变量类型,这是因为go可以类型推导,也就是说会根据变量的值,来推导出变量的类型
2) 简短声明 只能用在函数内部
2
3
4
5
# 2.2.5 批量声明变量
var (
name string
age int
is_leader bool
)
当我们想要一次声明多个变量时,可以直接使用var () 来对多个变量同时声明
// 可以再一个声明语句中同时声明一组变量并赋值
var name,b = "tchua",2
// 也可以世界声明,不赋值
var i, j, k int
2
3
4
5
6
7
8
9
10
11
12
# 2.2.6 变量的初始值
变量在声明时,如果没有初始化赋值,那么变量的初始值,就是该类型的零值
var (
name string
age int
is_leader bool
)
fmt.Println(name) // 默认为空
fmt.Println(age) // 默认为0
fmt.Println(is_leader) // 默认为false
"""
数值类型变量对应的零值是0,布尔类型变量对应的零值是false,字符串类型对应的零
值是空字符串,接口或引用类型(包括slice、指针、map、chan和函数)变量对应的零值是
nil,数组或结构体等聚合类型对应的零值是每个元素或字段都是对应该类型的零值.
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.2.7 变量作用域
Go语言使用大括号显示的标识作用域范围,大括号内包含一连串的语句,叫做语句块。语句块可以嵌套,语句块内定义的变量不能在语句块外使用:
函数内定义的变量称为局部变量
函数外定义的变量称为全局变量
函数定义中的变量称为形式参数
2
3
4
- 局部变量
func main() {
name := "tchua"
if true {
fmt.Println(name)
}
}
// 局部变量重新赋值
func main() {
name := "tchua"
if true {
name = "a"
fmt.Println(name)
}
fmt.Println(name)
}
打印结果: a a
// 局部重新声明变量
func main() {
name := "tchua"
if true {
name := "a"
fmt.Println(name)
}
fmt.Println(name)
}
打印结果: a tchua
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 2.2.8 总结
- 变量类型
| 类型 | go变量类型 | fmt输出 |
|---|---|---|
| 整型 | int int8 int16 int32 in64 uint uint8 uint16 uint32 uint64 | %d |
| 浮点型 | float32 float64 | %f %e %g |
| 复数 | complex128 complex64 | %v |
| 布尔型 | bool | %t |
| 指针 | uintptr | %p |
| 引用类型 | channle map slice | %v |
| 字节 | byte | %c |
| 任意字符 | rune | %c |
| 字符串 | string | %s |
| 错误 | error | %v |
1、简短声明只能用于函数内部,不用用于全局声明
2、":="是一个变量声明语句,而"="是一个变量赋值操作
2
# 2.3 常量
# 2.3.1 声明定义
常量声明时需要使用const关键字,而且在声明时必须赋值,声明之后,变量值不可改变
const pi=3.14
2
# 2.3.2 iota
iota是go语言的常量计数器,只能在常量的表达式中使用。
//
iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
// 例1:
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)
// 例2: 使用 _ 跳过某些值
const (
n1 = iota //0
n2 //1
_
n4 //3
)
// 例3: iota声明中间插队
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 2.4 输入输出
Go使用
fmt标准库实现输入输出
# 2.4.1 标准输出
fmt中主要用于输出的函数有:
- Print: 输出到控制台,不接受任何格式化操作。
- Println: 输出到控制台并换行。
- Printf : 只可以打印出格式化的字符串。只可以直接输出字符串类型的变量(不可以输出别的类型)
- Sprintf:格式化并返回一个字符串而不带任何输出。
- Errorf:是根据传入的内容格式化后返回一个包含该字符串的error。
代码演示:Print、Println
package main
import "fmt"
func main() {
// Print 结尾不会有换行
fmt.Print("Print示例: 我是菜鸡...")
// Println 结尾有换行
fmt.Println("Println示例: 哈哈哈")
}
输出结果:
Print示例: 我是菜鸡...Println示例: 哈哈哈
2
3
4
5
6
7
8
9
10
11
12
13
14
代码演示: Printf
package main
import "fmt"
func main() {
// Printf 格式化 需要指定占位符
fmt.Printf("Printf示例: 我是%s\n", "tchua")
}
2
3
4
5
6
7
8
常用占位符
- 整数类型
| 格 式 | 描 述 |
|---|---|
| %b | 整型以二进制方式显示 |
| %o | 整型以八进制方式显示 |
| %d | 整型以十进制方式显示 |
| %x | 整型以十六进制方式显示 |
| %X | 整型以十六进制、字母大写方式显示 |
| %c | 相应Unicode码点所表示的字符 |
| %U | Unicode 字符, Unicode格式:123,等同于 "U+007B" |
- 浮点数
| 格 式 | 描 述 |
|---|---|
| %e | 科学计数法,例如 -1234.456e+78 |
| %E | 科学计数法,例如 -1234.456E+78 |
| %f | 有小数点而无指数,例如 123.456 |
| %g | 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 |
| %G | 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 |
- 布尔
| 格 式 | 描 述 |
|---|---|
| %t | true 或 false |
- 字符串
| 格 式 | 描 述 |
|---|---|
| %s | 字符串或切片的无解译字节 |
| %q | 双引号围绕的字符串,由Go语法安全地转义 |
| %x | 十六进制,小写字母,每字节两个字符 |
| %X | 十六进制,大写字母,每字节两个字符 |
- 指针
| 格 式 | 描 述 |
|---|---|
| %p | 十六进制表示,前缀 0x |
- 通用占位符
| 格 式 | 描 述 |
|---|---|
| %v | 值的默认格式。 |
| %+v | 类似%v,但输出结构体时会添加字段名 |
| %#v | 相应值的Go语法表示 |
| %T | 相应值的类型的Go语法表示 |
| %% | 百分号,字面上的%,非占位符含义 |
代码演示: Sprintf
package main
import "fmt"
func main() {
// Sprintf 返回一个字符串
s1 := fmt.Sprintf("Sprintf示例: 我是%s\n", "tchua")
fmt.Println(s1)
}
打印结果:
Sprintf示例: 我是tchua
2
3
4
5
6
7
8
9
10
11
12
13
Errorf
package main
import "fmt"
func main() {
// Errorf 返回一个字符串
s1 := fmt.Errorf("格式化出错:%s\n", "conn reset")
fmt.Println(s1)
}
打印结果:
格式化出错:conn reset
2
3
4
5
6
7
8
9
10
11
12
13
# 2.4.2 标准输入
格式化输入函数介绍
fmt包中提供了3类读取输入的函数:
- Scan家族:从标准输入os.Stdin中读取数据,包括Scan()、Scanf()、Scanln()
- SScan家族:从字符串中读取数据,包括Sscan()、Sscanf()、Sscanln()
- Fscan家族:从io.Reader中读取数据,包括Fscan()、Fscanf()、Fscanln()
补充
这3家族的函数都返回读取的记录数量,并会设置报错信息,例如读取的记录数量不足、超出或者类型转换失败等.
- Scanln、Sscanln、Fscanln在遇到换行符的时候停止
- Scan、Sscan、Fscan将换行符当作空格处理
- Scanf、Sscanf、Fscanf根据给定的format格式读取,就像Printf一样
3.4.2.1 Scan家族函数
Scan家族函数从标准输入读取数据时,以空格做为分隔符分隔标准输入的内容,并将分隔后的各个记录保存到给定的变量中,函数返回值为读取到的记录数和err信息。
scan
输入数据时可以换行输入,Scan()会将换行符作为空格进行处理,直到读取到了2个记录之后自动终止读取操作。
package main
import "fmt"
var (
name string
age int
)
func main() {
fmt.Print("请输入你的姓名和年龄: ")
fmt.Scan(&name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
// 执行程序后,会先等待用户输入或者从管道中读取,读取到的内容分别保存在变了name和age中
打印结果:
请输入你的年龄和年龄: tchua 18
姓名:tchua,年龄:18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Scanln
跟Scan函数类似,只是Scanln在遇到换行符或EOF的时候终止读取。
package main
import "fmt"
var (
name string
age int
)
func main() {
fmt.Print("请输入你的姓名和年龄: ")
fmt.Scanln(&name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
// 执行程序后,会先等待用户输入或者从管道中读取,读取到的内容分别保存在变了name和age中,回车会直接退出
打印结果:
请输入你的年龄和年龄: tchua 18
姓名:tchua,年龄:18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Scanf
Scanf 和 Scanln一样, 也是遇到换行符或EOF的时候终止读取, 只是Scanf需要指定字符串格式。
package main
import "fmt"
var (
name string
age int
)
func main() {
fmt.Print("请输入你的姓名和年龄: ")
fmt.Scanf("%s:%d", &name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
// 可以指定字符分隔符 比如" : "
打印结果:
请输入你的年龄和年龄: tchua 18
姓名:tchua,年龄:18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2.4.2.2 SScan家族
Sscan家族的函数用于从给定字符串中读取数据,用法和Scan家族类似。
Sscan
package main
import "fmt"
var (
name string
age int
)
func main() {
s1 := "tchua 18"
fmt.Sscan(s1, &name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
打印结果:
姓名:tchua,年龄:18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Scanln
遇到换行符则结束读取
package main
import "fmt"
var (
name string
age int
)
func main() {
s1 := "tchua \n 18"
fmt.Sscanln(s1, &name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
打印结果:
姓名:tchua,年龄:0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Sscanf
和Scanf一样,格式完全自己定义
package main
import "fmt"
var (
name string
age int
)
func main() {
s1 := "tchua : 18"
fmt.Sscanf(s1, "%s : %d", &name, &age)
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2.5 流程控制
# 2.6 基础数据类型
# 三、复合数据类型
# 3.1 数组
# 3.1.1 数组存储方式
当在Go中声明一个数组之后,会在内存中开辟一段固定长度的、连续的空间存放数组中的各个元素,这些元素的数据类型完全相同,可以是内置的简单数据类型(int、string等),也可以是自定义的struct类型。
固定长度:这意味着数组不可增长、不可缩减。想要扩展数组,只能创建新数组,将原数组的元素复制到新数组
连续空间:这意味可以在缓存中保留的时间更长,搜索速度更快,是一种非常高效的数据结构,同时还意味着可以通过数值index的方式访问数组中的某个元素
数据类型:意味着限制了每个block中可以存放什么样的数据,以及每个block可以存放多少字节的数据
2
3
4
5
# 3.1.2 数组声明
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var variable_name [SIZE] variable_type
示例:
var a1 [3]int // 声明一个长度为3的数组
2
3
4
5
# 3.1.3 数组默认值
数组声明后,如果没有初始值,那么数组的元素值,就是对应数组类型的零值。
如果声明一个数组长度为3,我们初始值只给了2个,那么剩下一个会用该类型的零值填充。
2
# 3.1.4 数组声明并赋值
数组赋值有两种方式,第一种是声明后复制,第二种是声明的时候直接给默认值。
// 声明后赋值
var a1 [3]int
a1[0] = 1
a1[1] = 2
a1[2] = 3
// 声明并赋值
var a1 [3]int{1,2,3}
// 如果在数组的长度位置出现的是“...”省略号,则表示数组的长度是根据初始化值的个数来计算
a1 := [...]int{1,2,3}
// 定义一个包含100个元素的数组,其他位置使用0填充
a2 := [...]int{99:1011}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3.1.5 数组类型
数组类型不能仅仅通过定义的时候指定的来判断,比如,我们声明两个int类型数组,分别如下:
func main() {
var a1 [3]int
var a2 [4]int
fmt.Printf("%T\n",a1)
fmt.Printf("%T",a2)
}
打印结果:
[3]int
[4]int
虽然a1 a2都是int类型,但数组的数据类型是两部分组成的[n]TYPE,这个整体才是数组的数据类型。所以,[3]int和[4]int是两种不同的数组类型。
2
3
4
5
6
7
8
9
10
11
# 3.1.6 数组访问修改
数组访问修改时,都可以通过索引值进行操作
func main() {
var a1 = [3]int{11,22,33}
fmt.Println(a1[0])
fmt.Println(a1[1])
fmt.Println(a1[2])
}
// 数组遍历 for range
func main() {
var a1 = [3]int{11,22,33}
for i,v := range a1{
fmt.Println(i,v)
}
}
打印结果:---> i 取索引值,v 取元素
0 11
1 22
2 33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 3.1.7 指针数组
声明数组时,我们也可以直接声明一个指针类型的数组,这样数组中就可以存放指针。指针的默认值为nil。
// 声明一个长度为3的指针类型数组
var a1 = [3]*int // 默认值为nil
fmt.Println(a1)
打印结果: [<nil> <nil> <nil>]
// 赋值
a1[0] = new(int) // new返回括号内类型的零值的指针
*a1[0] = 10
// 声明并赋值
var a1 = [3]*int{new(int),new(int),new(int)}
fmt.Println(a1)
打印结果: [0xc000014098 0xc0000140b0 0xc0000140b8]
2
3
4
5
6
7
8
9
10
11
12
13
14
- 注意
如果,声明指针,不初始化,进行访问的时候,会报空指针异常,因为,指针地址为nil,等于说并没有为元素开辟内存空间。
例如:
a1 := [3]*int
*a1[0] = 1 // 直接给索引为0的元素赋值,由于并没有开辟内存空间,所以这样是错误的,无法直接赋值。
2
3
4
5
# 3.1.8 数组拷贝
在Go中,由于数组算是一个值类型,所以可以将它赋值给其它数组 因为数组类型的完整定义为[n]TYPE,所以数组赋值给其它数组的时候,n和TYPE必须相同。
示例: 数组copy实际就是复制一个完整的数组,等于再开辟一个新的空间
func main() {
a1 := [3]int{1,2,3}
a2 := a1
fmt.Println("修改之前",a1,a2)
a2[0] = 1111
fmt.Println("修改之后",a1,a2)
}
打印结果:
修改之前 [1 2 3] [1 2 3]
修改之后 [1 2 3] [1111 2 3]
总结: 数组copy 数据修改是并不会影响另一个数组的值,因为,属于不同的内存空间,如果是指针类型的数组,copy的是元素的地址,所以修改对应的值,对另一个数组的元素也会有影响。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3.1.9 多维数组
// 定一个长度为4,内部数组长度为2的二维数组
var a1 = [4][2]int{{1,2},{3,4},{5,6},{7,8}}
2
# 3.1.10 数组内存管理
- 示例1
func main() {
var a1 [3]int8
fmt.Printf("数组%p\n",&a1)
fmt.Printf("第一个元素内存地址%p\n",&a1[0])
fmt.Printf("第二个元素内存地址%p\n",&a1[1])
fmt.Printf("第三个元素内存地址%p\n",&a1[2])
}
打印结果:
数组0xc000014098
第一个元素内存地址0xc000014098
第二个元素内存地址0xc000014099
第三个元素内存地址0xc00001409a
"""
int8 类型 8位 等于一个字节
可以看到内存地址连续的并且相邻元素内存地址相差值为int8类型的长度
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 示例2
func main() {
var a1 = [3]int32{11,22,33}
fmt.Printf("数组%p\n",&a1)
fmt.Printf("第一个元素内存地址%p\n",&a1[0])
fmt.Printf("第二个元素内存地址%p\n",&a1[1])
fmt.Printf("第三个元素内存地址%p\n",&a1[2])
}
打印结果:
数组0xc0000140b0
第一个元素内存地址0xc0000140b0
第二个元素内存地址0xc0000140b4
第三个元素内存地址0xc0000140b8
"""
int32 32位 4个字节
元素地址相差4个字节
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 实例3
func main() {
var a1 = [3]string{"tchua","小花花"}
fmt.Printf("数组%p\n",&a1)
fmt.Printf("第一个元素内存地址%p\n",&a1[0])
fmt.Printf("第二个元素内存地址%p\n",&a1[1])
fmt.Printf("第三个元素内存地址%p\n",&a1[2])
}
打印结果:
数组0xc0000c2390
第一个元素内存地址0xc0000c2390
第二个元素内存地址0xc0000c23a0
第三个元素内存地址0xc0000c23b0
"""
字符串内部存储:len + str ,len 8个字节,str8个字节
len: 字符串长度 str: 指针,指向字符串对应的值
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 总结
1、数组声明后,会自动开辟内存空间。(空间大小与数组类型有关)
2、数组地址是连续的,相邻的元素之前相差的大小,就是数组类型对应的大小
3、数组内存地址与数组中第一个元素的地址相同
2
3
# 3.2 切片(slice)
# 3.2.1 切片介绍
Go中的slice依赖于数组,它的底层就是数组,所以数组具有的优点, slice都有。 且slice支持可以通过append向slice中追加元素,长度不够时会动态扩展,通过再次slice切片,可以得到得到更小的slice结构,可以迭代、遍历等
每一个slice结构都由3部分组成:
容量(capacity): 即底层数组的长度,表示这个slice目前最多能容纳多少个元素
长度(length):表示slice当前的长度,即当前容纳的元素个数
数组指针(array): 指向底层数组的指针
2
3
4
5
6
# 3.2.2 切片初始化
// make初始化 长度为3,容量为5的数组
a1 := make([]int,3,5)
// 省略容量 默认长度==容量,表示长度与容量都为3
a1 := make([]int,3)
注意: 切片初始化定义时,长度不能超过指定的容量
a1 := make([]int,5,3) // 编译不通过
// 也可以像数组一样直接创建,初始的长度和容量会基于初始化时提供的元素的个数确定
a1 := []int(1,2,3)
// 只声明
var a1 []int
// 初始化
a1 = []int{11,22,33}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3.2.3 切片访问
切片访问与数组一样,都是可以通过索引位置的方式进行访问
s := []int{1,2,3}
fmt.Println(s[0])
// 查看切片长度
fmt.Println(len(s))
// 查看切片容量
fmt.Println(cap(s))
2
3
4
5
6
7
# 3.3.4 切片新增与自动扩容
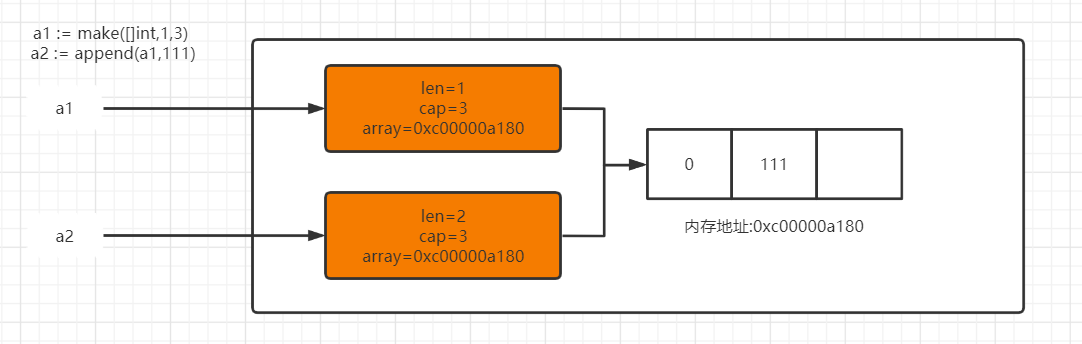
- 新增
// 新增元素不超过切片容量
func main() {
a1 := make([]int,1,3)
fmt.Println("扩容前a1",a1)
fmt.Printf("扩容前a1内存地址:%p\n",a1)
a2 := append(a1,111)
fmt.Println("扩容后a1",a1)
fmt.Printf("扩容后a1内存地址:%p\n",a1)
fmt.Println("a2",a2)
fmt.Printf("a2内存地址:%p\n",a2)
fmt.Println("a2 切片长度与容量",len(a2),cap(a2))
fmt.Println("a1 切片长度与容量",len(a1),cap(a1))
}
打印结果:
扩容前a1 [0]
扩容前a1内存地址:0xc00000a180
扩容后a1 [0]
扩容后a1内存地址:0xc00000a180
a2 [0 111]
a2内存地址:0xc00000a180
a2 切片长度与容量 2 3
a1 切片长度与容量 1 3
"""
从结果可以分析出来:
1、append后a2、a1内存地址相同
2、a1、a2切片容量相同,长度不同、所以获取到的值不同
3、append() 如果直接接一个切片,则需要使用解包的方式
append(a1,[]int{1,2,3}...)
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 自动扩容
// 这次我们直接往切片a1中添加3个元素,由于超过初始容量,会触发切片的自动扩容
// 切片底层扩容原理: 在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25%的容量(随着语言的演化,这种增长算法可能会有所改变)
func main() {
a1 := make([]int,1,3)
fmt.Println("扩容前a1",a1)
fmt.Printf("扩容前a1内存地址:%p\n",a1)
a2 := append(a1,111,333,444)
fmt.Println("扩容后a1",a1)
fmt.Printf("扩容后a1内存地址:%p\n",a1)
fmt.Println("a2",a2)
fmt.Printf("a2内存地址:%p\n",a2)
fmt.Println("a2 切片长度与容量",len(a2),cap(a2))
fmt.Println("a1 切片长度与容量",len(a1),cap(a1))
}
打印结果:
扩容前a1 [0]
扩容前a1内存地址:0xc00000a180
扩容后a1 [0]
扩容后a1内存地址:0xc00000a180
a2 [190 111 333 444]
a2内存地址:0xc00000c3f0
a2 切片长度与容量 4 6
a1 切片长度与容量 1 3
"""
从结果可以分析:
1、a1、a2 内存地址不同,扩容后等于是一个新的切片
2、a2容量是a1的容量2倍
3、a1与a2已经是不同的切片
切片自动扩容后,新的切片与原切片不在共享底层数据
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
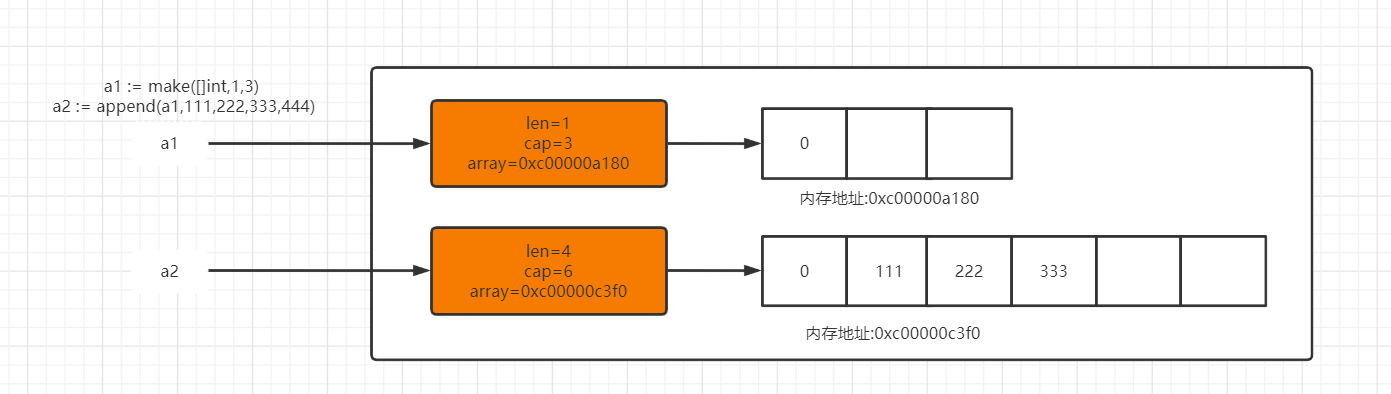
- 总结
切片追加元素时,在不会产生扩容的情况下,append之后产生的新切片和原切片引用同1个底层数组。一旦出现了扩容就会产生1个新的底层数组来保存原来的数据和新的数据。所以新、旧切片使用了2个不同的底层数组。它们之间的修改操作不再彼此影响!
# 3.2.4 切片的切片
a1 := []int{11,22,33,44,55,66}
a2 := a1[2:4]
fmt.Println(a2) // [33,44] 左闭右开原则
注意: 通过切片创建出的切片与原切片共享底层数据
2
3
4
5
# 3.3 结构体
# 3.3.1 结构体介绍及定义
结构体是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员。
结构体定义使用 struct 标识,需要指定其包含的属性(名和类型),在定义结构体时可以为 结构体指定结构体名(命名结构体),用于后续声明结构体变量使用.
type student struct {
name string
id int
age int
}
2
3
4
5
6
7
8
# 3.3.2 声明与初始化
上面我们仅仅定义了结构体,接下来我我们介绍下如何进行声明与初始化值
- 声明
type Student struct {
name string
id int
age int
}
func main() {
var student Student
fmt.Printf("%+v\n", student)
}
打印结果:
{name: id:0 age:0} // 只声明后结构体的所有属性都是对应类型的初始值
2
3
4
5
6
7
8
9
10
11
12
- 声明并初始化
type Student struct {
name string
id int
age int
}
func main() {
var student Student = Student{
name: "小花",
id: 1204,
age: 22,
}
fmt.Printf("%+v",student)
}
打印结果:
{name:小花 id:1204 age:22}
注意: 字段后面的 ',' 号不能省略
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.3.3 结构体访问
结构体访问,可以通过 结构体.属性 的方法
fmt.Println(student.name)
// 修改
student.age = 25
2
3
4
5
# 3.3.4 结构体指针
- 声明
type Person struct {
Name string
Age int
}
func main() {
var person *Person
fmt.Println(person) // nil
}
2
3
4
5
6
7
8
9
- 声明并初始化
type Person struct {
Name string
Age int
}
func main() {
var person *Person = &Person{
Name: "tchua",
Age: 18,
}
fmt.Printf("%p",person)
}
2
3
4
5
6
7
8
9
10
11
12
- new创建指针对象
type Person struct {
Name string
Age int
}
func main() {
person := new(Person)
fmt.Printf("%p",person)
}
2
3
4
5
6
7
8
9
# 3.3.5 结构体方法
package main
import "fmt"
// 结构体方法可以 进行一些结构体内部数据处理,然后返回给客户端
type Person struct {
Name string
Age int
}
func FuncPerson(p *Person){
p.Age = 29
}
// 属于数据结构的函数,可以为数据结构定义属于自己的函数
func main() {
p := Person{
Name: "tchua",
Age: 18,
}
FuncPerson(&p)
fmt.Println(p.Age)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 3.3.6 结构体嵌套
- 命名嵌套
结构体命名嵌入是指结构体中的属性对应的类型也是结构体
type Person struct {
Name string
Age int
Ad Address // 有名嵌套结构体,字段类型直接就是结构体名称
}
type Address struct {
address string
}
func main() {
p1 := Person{
Name: "tchua",
Age: 18,
Ad: Address{
address: "河南省兰考县",
},
}
fmt.Println(p1.Name)
fmt.Println(p1.Age)
fmt.Println(p1.Ad.address) // 有名嵌套访问的时候,需要指定嵌套的结构体名称,才可以访问到嵌套的结构体属性
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 匿名嵌套
type Person struct {
Name string
Age int
Address // 匿名嵌套,直接写结构体名称即可
}
type Address struct {
address string
}
func main() {
p1 := Person{
Name: "tchua",
Age: 18,
Address: Address{ // 初始化时,需要指定结构体名称
address: "河南省兰考县",
},
}
fmt.Println(p1.Name)
fmt.Println(p1.Age)
fmt.Println(p1.address) // 访问的时候不需要再指定嵌套的结构体名称,直接 `.结构体` 属性即可
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 3.3.7 结构体内存对齐
type A struct {
a bool
b int32
c string
d string
}
type B struct {
b int32
c string
d string
a bool
}
fmt.Println(unsafe.Sizeof(A{})) // 40
fmt.Println(unsafe.Sizeof(B{})) // 48
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
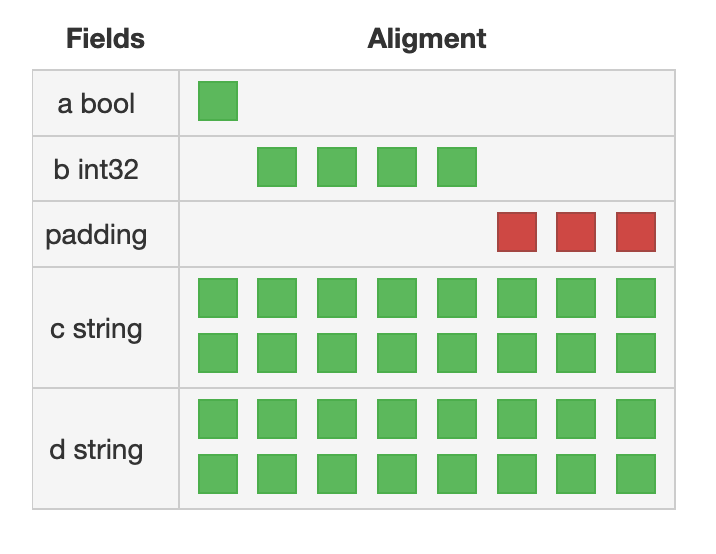
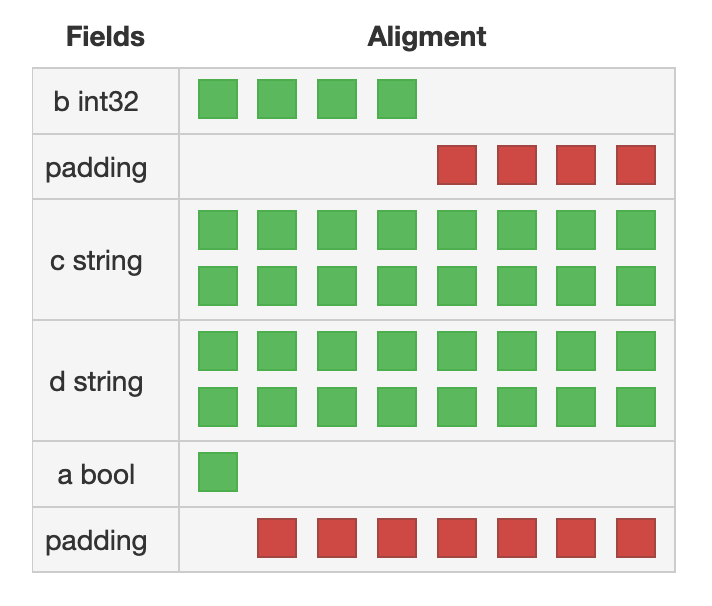
- 总结
前提: 32位系统上按4bytes对齐,64位系统上按8bytes对齐
通过上面两个图,以及程序打印结果可以看出:
A.a 一个字节
A.b int32 4个字节
A.c string 16个字节
A.d string 16个字节
a+b=5个字节 后面填充3位对齐 --> 1 + 4 + 3 = 8
c d 都可以自行对齐 所以无需填充 --> 16 + 16 =32
B.b 4 个字节
B.c 16 个字节
B.d 16 个字节
B.a 1 个字节
b 4个字节需要使用4位填充 --> 4 + 4 = 8
c d 都是16字节 后面无需填充 --> 16 + 16 = 32
a 1个字节 因为后面也没有字段,所以需要使用7位填充 --> 1 + 7 = 8
所以,合理重排字段可以减少填充,使struct字段排列更紧密
// 零大小字段对齐
零大小字段(zero sized field)是指struct{},大小为 0,按理作为字段时不需要对齐,但当在作为结构体最后一个字段(final field)时需要对齐的。即开篇我们讲到的面试题的情况,假设有指针指向这个final zero field, 返回的地址将在结构体之外(即指向了别的内存),如果此指针一直存活不释放对应的内存,就会有内存泄露的问题(该内存不因结构体释放而释放),go 会对这种final zero field也做填充,使对齐。当然,有一种情况不需要对这个final zero field做额外填充,也就是这个末尾的上一个字段未对齐,需要对这个字段进行填充时,final zero field就不需要再次填充,而是直接利用了上一个字段的填充。
type A struct {
a bool
b int32
c string
d string
}
type B struct {
b int32
c string
d string
a int64
e struct
}
fmt.Println(unsafe.Sizeof(A{})) // 40
fmt.Println(unsafe.Sizeof(B{})) // 56
零大小字段要避免作为 struct 最后一个字段,会有内存浪费,也就是说最后一个字段不是struct{}的时候,struct{}不会占用空间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 3.3.8 结构体工厂模式
package main
import "fmt"
// 定义File结构体
type File struct {
fd int
name string
}
// 构建用于初始化结构体的函数
func NewFile(fd int,name string) *File {
if fd < 0{
return nil
}
return &File{fd,name}
}
func main() {
// 调用时,直接传入参数
f := NewFile(12,"huahua")
fmt.Println(f.name)
fmt.Println(f.fd)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3.3.9 结构体标签
Go语言结构体标签,就是在结构体中的一段字符串,通常用于反射包里的方法来访问它,标签用来声明结构体中字段的属性。
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Name string `json:"username"`
Age int `json:"userage"`
Salary int `json:"usersalary"`
}
func main() {
myself := User{
Name: "唐春",
Age: 22,
Salary: 10,
}
// json.Marshal()方法作用就是把结构体转换为json,对应的字段名为标签对应的值
jsdata,err := json.Marshal(myself)
if err != nil {
fmt.Println("格式错误")
} else {
fmt.Printf("User结构体转json:%s\n",jsdata)
}
}
打印结果:
"""
User结构体转json:{"username":"唐春","userage":22,"usersalary":10}
"""
可以看出"encoding/json"包的json.Marshal()方法作用就是把结构体转换为json,它读取了User结构体里面的标签,json键值对的键为定义的标签名,结构体的名字起了辅助作用,同时定义了字段数据类型。json.Unmarshal()可以把json字符串转换为结构体,在很多第三方包方法都会读取结构体标签。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 3.4 字符串
# 3.4.1 字符串介绍
字符串是 Go 语言中的基础数据类型,虽然字符串往往被看做一个整体,但是它实际上是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,go语言中的字符串实际上是类型为byte的只读切片
# 3.4.2 byte和rune类型
组成每个字符串的元素叫做"字符",可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号('')包裹起来,如:
a1 := 'a'
a2 := '你'
Go语言的字符有以下两种:
- 第一种是 uint8类型,也叫做byte型, 长度为 1 个字节,用于表示 ASCII 字符
- 第二种是 rune类型,也叫做int32,长度为 4 个字节,用于表示以 UTF-8 编码的 Unicode 码点
示例:
func main() {
// 明确指定字符类型为byte(uint8) 字符类型为ASCII
var a1 byte = 'a'
// 不指定字符类型 字符类型 默认为int32 =rune类型
var a2 = 'a'
// int32 =rune类型
var a3 = '你'
fmt.Printf("Unicode对应的字符: %v 值:%c 字符类型%T\n",a1,a1,a1)
fmt.Printf("Unicode对应的字符: %v 值:%c 字符类型%T\n",a2,a2,a2)
fmt.Printf("Unicode对应的字符: %v 值:%c 字符类型%T\n",a3,a3,a3)
}
打印结果:
Unicode对应的字符: 97 值:a 字符类型uint8
Unicode对应的字符: 97 值:a 字符类型int32
Unicode对应的字符: 20320 值:你 字符类型int32
如果在声明一个字符变量时没有指明类型,Go 会默认它是 rune 类型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.4.3 单引号 双引号 反引号
- 单引号 在golang中表示一个字符
var a1 byte = 'a' // ASCII编码的a
var a2 = 'a' // utf-8编码的a
2
- 双引号 go创建字符串的
// 支持转义
str1 := "hello 中国"
str2 := "hello \n word"
2
3
- 反引号
// 不支持转义,支持多行
a1 := `
床前明月光
疑是地上霜
`
2
3
4
5
# 3.4.4 字符串长度
如果想要计算字符串长度,可能很多人都想到使用len,其实使用en求出的长度并不是字符串可看到的那样,因为len表示的是字符串的 ASCII字符的个数或者字节长度,如果想要切除字符串的真是长度需要使用utf8.RuneCountString
func main() {
a1 := "hello word let is go"
a2 := "hello"
a3 := "hello 小哥"
a4 := "小哥"
fmt.Printf("字符串:%v,字符长度:%d,字符真实长度:%d\n",a1,len(a1),utf8.RuneCountInString(a1))
fmt.Printf("字符串:%v,字符长度:%d,字符真实长度:%d\n",a2,len(a2),utf8.RuneCountInString(a2))
fmt.Printf("字符串:%v,字符长度:%d,字符真实长度:%d\n",a3,len(a3),utf8.RuneCountInString(a3))
fmt.Printf("字符串:%v,字符长度:%d,字符真实长度:%d\n",a4,len(a4),utf8.RuneCountInString(a4))
}
打印结果:
字符串:hello word let is go,字符长度:20,字符真实长度:20
字符串:hello,字符长度:5,字符真实长度:5
字符串:hello 小哥,字符长度:12,字符真实长度:8
字符串:小哥,字符长度:6,字符真实长度:2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.4.5 字符串遍历
遍历字符串有两种比方式,一种下标方式,另一种是使用range
- 下标
由于在 Go 语言中,字符串以 UTF-8 编码方式存储,使用 len() 函数获取字符串长度时,获取到的是该 UTF-8 编码字符串的字节长度,通过下标索引字符串将会产生一个字节。因此,如果字符串中含有 UTF-8 编码字符,就会出现乱码:
func main() {
a1 := "hello 小哥"
for i := 0; i < len(a1); i ++ {
fmt.Printf("%c 的类型是%s\n",a1[i],reflect.TypeOf(a1[i]))
}
}
2
3
4
5
6
7
8
- range
range遍历则会得到rune类型的字符
// range循环迭代时,就会解码一个utf-8编码的rune
func main() {
a1 := "hello 小哥"
for _,i := range a1 {
fmt.Printf("%c\n",i)
}
}
2
3
4
5
6
7
8
# 3.4.6 字符串拼接
// 使用 + 号
func main() {
a1 := "http://www:tchua.cn"
a2 := "/api"
a3 := a1 + a2
fmt.Println(a3)
}
2
3
4
5
6
7
8
9
# 3.4.7 字符串修改
// 要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func main() {
a1 := "8080"
fmt.Println(a1)
// 转
sByte := []byte(a1)
sByte[len(sByte) - 1] = '1'
a1 = string(sByte)
fmt.Println(a1)
}
2
3
4
5
6
7
8
9
10
# 3.4.8 string
- 判断是否存在某个字符或子串
func main() {
a1 := "hello word tchua"
// 字符串包含word字符 返回true 否则false
fmt.Println(strings.Contains(a1,"word"))
// 字符串包含任意指定的字符 即可返回true
fmt.Println(strings.ContainsAny(a1,"h "))
// 查找run类型
fmt.Println(strings.ContainsRune(a1,rune('a')))
}
2
3
4
5
6
7
8
9
10
11
- 字符串分割(切分)为[]string
a1 := "http://www.tchua.cn:8080/v1/goods"
a2 := "info.kafka.env"
// 以 / 为分隔符 返回一个新的切片
s1 := strings.Split(a1, "/")
fmt.Println(s1)
// 以 / 为分隔符 返回一个新的切片 并保留分隔符 "/"
s2 := strings.SplitAfter(a1, "/")
fmt.Println(s2)
// 以 / 为分隔符 保留2个 如果后面还有可以分割的 也不会分割
s3 := strings.SplitN(a2,".",2)
fmt.Println(s3)
2
3
4
5
6
7
8
9
10
11
12
- 字符串是否有某个前缀或后缀
a2 := "info.kafka.env"
// 以什么什么开头
fmt.Println(strings.HasPrefix(a2,"info"))
// 以什么什么结尾
fmt.Println(strings.HasSuffix(a2,"env"))
2
3
4
5
6
- 字符串修剪
func main() {
a1 := " www.tchua.comww"
fmt.Println(strings.Trim(a1,"w")) // 删除两边w,如果两边有多个w,会都删除
fmt.Println(strings.TrimLeft(a1,"w")) // 只删除左边w
fmt.Println(strings.Trim(a1,"w")) // 只删除右边w
// 如果前缀以w开头,则删除w,否则返回原字符串,只删除一次(只删除匹配到的w,不会多次删除)
fmt.Println(strings.TrimPrefix(a1,"w"))
// 如果以w后缀,则删除w,否则返回原字符串,只删除一次(只删除匹配到的w,不会多次删除)
fmt.Println(strings.TrimSuffix(a1,"w"))
// 去除字符串两遍空格
fmt.Println(strings.TrimSpace(a1))
// 结合函数,匹配到的内容会被删除(左右两边)
f := func (r rune) bool {
return unicode.Is(unicode.Han,r)
}
fmt.Println(strings.TrimFunc("he小llo 小花",f))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 字符串连接join
// a1 := "http://www.tchua.com/api?"
a2 := strings.Join([]string{"name=tchua","age=20"},"&")
fmt.Println(a2)
2
3
4
5
- 字符串替换
func main() {
a1 := "hello word"
// 把word 换成go 1就是换一次 如果小于0 就是全部替换
fmt.Println(strings.Replace(a1,"word","go",1))
}
2
3
4
5
6
- 大小写转换
func main() {
a1 := "Abc"
// 转小写
fmt.Println(strings.ToLower(a1))
// 转大写
fmt.Println(strings.ToUpper(a1))
}
2
3
4
5
6
7
8
9
10
- 字符串拼接的优化
// string.builder
func main() {
a1 := []string{"A","B","C"}
var b strings.Builder
for _,s := range a1 {
b.WriteString(s)
}
fmt.Println(b.String())
}
2
3
4
5
6
7
8
9
10
# 3.5 map
# 3.5.1 map声明
// map 声明需要指定组成元素 key 和 value 的类型,在声明后,会被初始化为 nil,表示 暂不存在的映射
var m map[string]string // 只声明无法给变量初始化值
// make声明初始化
m := make(map[string]string)
m["name"] = "tchua"
// 直接初始化
m := map[string]int{"name": "tchua", "age": 55}
2
3
4
5
6
7
3.5.2 map增删改查
func main() {
m := make(map[string]string)
// 增
m["name"] = "tchua"
m["age"] = "18"
fmt.Println(m)
// 删
delete(m,"name")
fmt.Println(m)
// 改
m["age"] = "20"
fmt.Println(m)
// 查
a1 := m["age"]
fmt.Println(a1)
a2,err := m["age"]
fmt.Println(a2,err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 3.5.2 map遍历
- 遍历key和value
m := make(map[string]int)
// 造数据
for i := 1;i < 8; i ++ {
key := fmt.Sprintf("id_%d",i)
m[key] = i
}
// 循环遍历
for k,v := range m {
fmt.Println(k,v)
}
// 循序打印 k v
func main() {
m := make(map[string]int)
keys := make([]string,0)
for i := 1;i < 8; i ++ {
key := fmt.Sprintf("id_%d",i)
m[key] = i
// 把key有序放入切片,后面直接遍历切边取值
keys = append(keys, key)
}
for _,i := range keys {
v := m[i]
fmt.Printf("%s=%d\n",i,v)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 遍历key
m := make(map[string]int)
// 造数据
for i := 1;i < 8; i ++ {
key := fmt.Sprintf("id_%d",i)
m[key] = i
}
// 循环遍历
for k := range m {
fmt.Println(k)
}
注意:map是无序的。
2
3
4
5
6
7
8
9
10
11
# 3.5.3 value类型
当map的value类型为map类型时,也是需要再make才可以
func main() {
m := make(map[string]map[string]string)
v := make(map[string]string)
v["v1"] = "k1"
m["name"] = v
fmt.Println(m["name"])
}
2
3
4
5
6
7
8
9
# 3.5.4 map线程安全
go原生map不安全
// 同时读写map fatal error: concurrent map read and map write
func main() {
m := make(map[int]int)
go func() {
for i := 0;i < 100000;i ++ {
m[i] = i
}
}()
go func () {
for i := 0; i<100000;i ++{
_ = m[i]
}
}()
time.Sleep(20*time.Second)
}
// 同时写map fatal error: concurrent map writes
func main() {
m := make(map[int]int)
go func() {
for i := 0; i < 100000; i++ {
m[i] = i
}
}()
go func() {
for i := 0; i < 100000; i++ {
m[i] = i
}
}()
time.Sleep(20 * time.Second)
}
总结:
可以看到,当我们对map进行大批量同时读写时,就会出现线程不安全的问题,针对go原生线程不安全问题,下面我们看下解决方案。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
- 解决方案一 加锁
// 定义结构体
type concurrentMap struct {
sync.RWMutex
m map[int]int
}
// 为结构体创建Set方法
func (c *concurrentMap) Set(key int,value int) {
// 先获取写锁
c.Lock()
// 写数据
c.m[key] = value
// 释放锁
c.Unlock()
}
// 为结构体创建Get方法
func (c *concurrentMap) Get(key int) int {
// 获取读锁
c.RLock()
// 读取数据
res := c.m[key]
// 释放读锁
c.RUnlock()
return res
}
func main() {
// 结构体初始化
c := concurrentMap {
m: make(map[int]int),
}
// 写入数据,调用结构体Set方法
go func() {
for i := 0; i < 100000; i++ {
c.Set(i,i)
}
}()
// 读数据,调用结构体Get方法
go func() {
for i := 0; i < 100000; i++ {
res := c.Get(i)
fmt.Printf("%d=%d\n",i,res)
}
}()
time.Sleep(20 * time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
- 解决方案二 sync.map
func main() {
// 定义初始化
c := sync.Map{}
// 存数据 value不仅限于同一种数据类型
c.Store("name", "tchua")
// c.Store("age", 18)
// 数据读取
fmt.Println(c.Load("age"))
// 删除数据
c.Delete("name")
// 遍历 Range遍历 Range套函数固定写法
// 如果返回false 则遍历结束
c.Range(func(k, v interface{}) bool {
key := k.(string)
value := v.(string)
fmt.Println(key, value)
return true
})
// LoadOrStore 读取数据,若不存在则保存再读取
c.LoadOrStore("name1", "huahua")
fmt.Println(c.Load("name1"))
// LoadAndDelete 如果删除的key存在 则打印要删除的key
v, err := c.LoadAndDelete("name")
fmt.Println(v, err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 3.5.5 分片锁 并发map
package main
import (
"fmt"
"github.com/orcaman/concurrent-map"
"time"
)
func main() {
m := cmap.New()
// 写map的 go
go func() {
for i := 0; i < 1000; i++ {
key := fmt.Sprintf("key_%d", i)
m.Set(key, i)
}
}()
time.Sleep(5*time.Second)
go func() {
for i := 0; i < 1000; i++ {
key := fmt.Sprintf("key_%d", i)
v, exists := m.Get(key)
if exists {
fmt.Println(v.(int), exists)
}
}
}()
time.Sleep(100 * time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 3.5.6 带过期时间的map
package main
import (
"fmt"
"log"
"sync"
"time"
)
// 定义结构体 存储map值和时间戳
type item struct {
value int
ts int64
}
// 定义结构体 map
type Cache struct {
sync.RWMutex
mp map[string]*item
}
// 结构体绑定方法 Get 查询key
func (c *Cache) Get(key string) *item {
c.RLock()
res := c.mp[key]
c.RUnlock()
return res
}
// 结构体绑定方法 Set 设置key
func (c *Cache) Set(key string,v *item) {
c.Lock()
c.mp[key] = v
defer c.Unlock()
}
// 结构体绑定方法 Gc 遍历value的过期时间
func (c *Cache) Gc(timeDelta int64) {
for {
toDelKeys := make([]string,0)
now := time.Now().Unix()
c.RLock()
for k,v := range c.mp{
if now - v.ts > timeDelta {
log.Printf("[这个项目已经过期][key %s]",k)
toDelKeys = append(toDelKeys, k)
}
}
c.RUnlock()
// 删除过期的key
c.Lock()
for _,k := range toDelKeys{
delete(c.mp,k)
}
c.Unlock()
time.Sleep(5 * time.Second)
}
}
func main() {
// 初始化 结构体
c := Cache{
mp: make(map[string]*item),
}
go c.Gc(30)
// 往结构体 塞入数据
for i := 0; i < 10; i ++ {
key := fmt.Sprintf("key_%d",i)
ts := time.Now().Unix()
im := &item {
value: i,
ts: ts,
}
// 设置缓存
log.Printf("[设置缓存][项目][key:%s][v:%v]",key,im)
c.Set(key,im)
}
time.Sleep(31*time.Second)
// 更新数据
for i := 0;i < 5; i ++ {
key := fmt.Sprintf("key_%d",i)
ts := time.Now().Unix()
im := &item{
value: i,
ts: ts,
}
log.Printf("[更新缓存][项目][key:%s][v:%v]", key, im)
c.Set(key, im)
}
select {}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
# 3.5.8 map几种方式的性能对比
// https://studygolang.com/articles/27515
只读场景:sync.map > rwmutex >> mutex
读写场景(边读边写):rwmutex > mutex >> sync.map
读写场景(读80% 写20%):sync.map > rwmutex > mutex
读写场景(读98% 写2%):sync.map > rwmutex >> mutex
只写场景:sync.map >> mutex > rwmutex
2
3
4
5
6
# 三、函数
# 3.1函数
# 3.1.1 定义
函数包含函数名、行参列表、函数体和返回值列表,使用func进行声明,函数无参数或返回值时则形参列表和返回值列表省略
形参列表需要描述参数名及参数类型,所有形参为函数块局部变量。返回值需要描述返回值类型
2
- 无参 无返回值
func sayHello() {
fmt.Println("hello")
}
2
3
- 有参数 无返回值
func sayHi(name string) {
fmt.Printf("hi %s",name)
}
2
3
- 有参数 有返回值
func add(a,b int) int {
return a + b
}
2
3
- 多返回值
// go语言支持函数有多个返回值,在声明函数时使用括号包含所有返回值类型,并使用return返回对应数量的用逗号分割数据
func op(a, b int) (int, int, int, int) {
return a + b, a - b, a * b, a / b
}
2
3
4
- 命名返回值
// 在函数返回值列表中可指定变量名,变量在调用时会根据类型使用零值进行初始化,在函数体中可进行赋值,同时在调用return时不需要添加返回值,go语言自动将变量的最终结果进行返回
func opv2(a, b int) (sum, sub, mul, div int) {
sum = a + b
sub = a - b
mul = a * b
div = a / b
return // 自动返回命名的返回值
}
func main() {
fmt.Println(opv2(1,2))
}
2
3
4
5
6
7
8
9
10
11
12
- 参数合并
在声明函数中若存在多个连续形参类型相同可只保留最后一个参数类型名
func fn(n1,n2,n3 int) {
fmt.Println(n1,n2,n3)
}
2
3
4
- 可变参数
某些情况下函数需要处理形参数量可变,需要运算符…声明可变参数函数或在调用时传递可变参数
func (n1,n2 int,args ...string){
fmt.Printf("%T %T %T",name)
fmt.Println(n1,n3,args) // args 返回该类型的切片
}
2
3
4
5
6
- 可变参数-->传递
func fn(n1,n2 int,args ...string) {
fmt.Println(n1,n2)
fmt.Println(args)
}
func main() {
//s1 := []string{"huahua","word"}
fn(1,2,[]string{"huahua","word"}...)
}
2
3
4
5
6
7
8
9
# 3.1.2 调用
函数通过函数名(实参列表),在调用过程中实参的每个数据会赋值给形参中的每个变量,因此实参列表类型和数量需要函数定义的形参一一对应。针对函数返回值可通过变量赋值的方式接收
# 3.1.3 函数类型
函数也可以赋值给变量,存储在数组、切片、映射中,也可作为参数传递给函数或作为函数返回值进行返回
func main() {
var callback func(n1,n2 int) (r1,r2,r3,r4 int)
fmt.Printf("%T,%v",callback,callback)
}
2
3
4
5
6
- 声明&调用参数类型为函数的函数
# 3.2 匿名函数
不需要定义名字的函数叫做匿名函数,常用做帮助函数在局部代码块中使用或作为其他函数的参数
func main() {
// 定义匿名函数 赋值给hi变量
hi := func(name string) {
fmt.Printf("Hi,%s\n",name)
}
// 调用匿名函数
hi("huahua")
}
// 定义匿名函数 并直接调用
func() {
fmt.Println("我是匿名函数")
}()
// 复杂一点的调用
// 函数参数为函数
func print(formatter func(string) string, args ...string) {
for i, v := range args {
fmt.Println(i, formatter(v))
}
}
func main() {
names := []string{"二狗子", "kk", "17-赵"}
star := func(txt string) string {
return "*" + txt + "*"
}
print(star, names...)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 3.2.1 闭包
匿名函数又叫闭包,是指在函数内定义的匿名函数引用外部函数的变量,只要匿名函数继续使用则外部函数赋值的变量不被自动销毁
func addBase(base int) func(int) int {
return func(num int) int {
return base + num
}
}
func main() {
add2 := addBase(2)
fmt.Printf("%T\n", add2)
fmt.Println(add2(10))
}
2
3
4
5
6
7
8
9
10
11
# 3.3 内置函数
# 3.3.1 new 和 make
内置函数new按指定类型长度分配零值内存,返回指针,并不关心类型内部构造和初始化方式。
内置函数make对引用类型进行创建,编译器会将make转换为目标类型专用的创建函数,以确保完成全部内存分配和相关属性初始化。
1、new(T) 返回的是 T 的指针
new(T) 为一个 T 类型新值分配空间并将此空间初始化为 T 的零值,返回的是新值的地址,也就是 T 类型的指针 *T,该指针指向 T 的新分配的零值。
2、make 只能用于 slice,map,channel
make 只能用于 slice,map,channel 三种类型,make(T, args) 返回的是初始化之后的 T 类型的值,这个新值并不是 T 类型的零值,也不是指针 *T,是经过初始化之后的 T 的引用。
2
3
4
5
6
7
8
9
10
11
12
# 3.4 递归
递归是指函数直接或间接调用自己,递归常用于解决分治问题,将大问题分解为相同的小问题进行解决,需要关注终止条件
- 计算阶乘
// 条件判断
func fn(n int) {
sum := 1
for i := 1;i <= n;i++{
if i < 1 {
break
}
sum = sum * i
}
fmt.Println(sum)
}
// 函数递归
func fn1(n int) int {
if n < 0 {
return -1
} else if n == 0{
return 1
} else {
return n * fn1(n - 1)
}
}
func main() {
fmt.Println(fn1(10))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 3.5 值类型&引用类型
值类型和引用类型的差异在于赋值同类型新变量后,对新变量进行修改是否能够影响原来的变量,若不能影响则为值类型,若能影响则为引用类型
# 3.5.1 值类型
在Go语言中参数传递默认均为值传递(形参为实参变量的副本),对于引用类型数据因其底层共享数据结构,所以在函数内可对引用类型数据修改从而影响函数外的原变量信息
package main
import "fmt"
func main() {
name := "huahua" // 字符串 值类型
nums := []int{1, 2, 3} // 切片 引用类型
// 定义匿名函数
func(pname string, pnums []int) {
// 1.参数 传递过来 打印 huahua, [1, 2, 3]
fmt.Println(pname, pnums) // huahua, [1, 2, 3]
// 是重新赋值
pname = "silence"
pnums = []int{1, 2,3,4,5}
// 2.切片重新赋值,内存指向改变 已经指向的不是同一个切片,所以修改不会影响
fmt.Println(pname, pnums) // silence, [1, 2]
}(name, nums)
/*
pname := name
pnums := nums
pname = "silence"
pnums = []int{1, 2}
*/
// 3.
fmt.Println(name, nums) // 1(v), 2
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.5.2 引用类型
package main
import "fmt"
func main() {
name := "kk"
nums := []int{1, 2, 3}
func(pname string, pnums []int) {
// 1.
fmt.Println(pname, pnums) // kk, [1, 2, 3]
pname = "silence"
pnums[0] = 100
// 2.
fmt.Println(pname, pnums) // silence [100, 2, 3]
}(name, nums)
/*
pname := name
pname = "silence"
pnums := nums
pnums[0] = 100
*/
// 3.
fmt.Println(name, nums) // kk, [100, 2, 3]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 3.6 defer
1) defer关键字用户声明函数,不论函数是否发生错误都在函数执行最后执行(return之前),若使用defer声明多个函数,则按照声明的顺序,先声明后执行(堆)
2) 常用来做资源释放,记录日志等工作
2
- 示例
fmt.Println("start")
// defer 函数调用
// defer 延迟执行
// 在函数退出之前执行
defer func() {
fmt.Println("defer")
}()
fmt.Println("end")
// start -> end -> defer
2
3
4
5
6
7
8
9
10
11
package main
import "fmt"
func div(n1,n2 int) (int,error) {
if n2 == 0 {
return 0,fmt.Errorf("被除数不能为零")
}
return n1 / n2,nil
}
func main() {
fmt.Println("start")
// defer 函数调用
// defer 延迟执行
// 在函数退出之前执行
defer func() {
fmt.Println("defer")
}()
// 多个defer 优先执行后面的 类似堆
defer func() {
fmt.Println("defer 2")
}()
fmt.Println("end")
// start -> end -> defer
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 四、面向对象和接口
# 4.1 接口
GO语言中的接口是一种特殊的数据类型
// 接口声明
type Name interface {
fun1(param_list) return_type
fun2(param_list) return_type
...
}
注意: 接口中的方法只定义,不实现具体的功能逻辑
2
3
4
5
6
7
8
# 4.1.1 空接口
代指任意类型
// 示例1
package main
import "fmt"
// 定义一个空接口
type Base interface {
}
func main() {
// 定义一个切片 指定类型为刚创建的空接口类型
dataList := make([]Base,0)
// 使用空接口 切片存储数据就不仅仅局限于同一种类型
dataList = append(dataList,"huahua")
dataList = append(dataList,18)
fmt.Println(dataList)
}
// 示例2
package main
import "fmt"
type Person struct {
name string
age int
}
func something(agrs interface{}) {
fmt.Println(agrs)
}
func main() {
something("huahua")
something(28)
something(Person{
name: "xiaohua",
age: 10,
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 4.1.2 非空接口
用于规范&约束
package main
import "fmt"
// 定义一个含有f1方法的接口
type IBase interface {
f1() int
}
// 结构体Person
type Person struct {
name string
}
// 结构体实现了接口IBase的f1方法
func (p Person) f1() int {
return 123
}
// 结构体User
type User struct {
name string
}
// 结构体User实现了接口IBase的f1方法
func (p User) f1() int {
return 666
}
// 定义函数 参数为接口类型
func DoSomething(base IBase) {
res := base.f1()
fmt.Println(res)
}
func main() {
per := Person{name: "huahua"}
user := User{name: "xiaohua"}
DoSomething(per)
DoSomething(user)
}
// 示例2
package main
import "fmt"
// 定义一个含有f1方法的接口
type IBase interface {
f1() int
}
// 结构体Person
type Person struct {
name string
}
// 结构体实现了接口IBase的f1方法
func (p *Person) f1() int {
fmt.Println(p.name)
return 123
}
// 结构体User
type User struct {
name string
}
// 结构体User实现了接口IBase的f1方法
func (p *User) f1() int {
fmt.Println(p.name)
return 666
}
// 定义函数 参数为接口类型
func DoSomething(base IBase) {
res := base.f1()
fmt.Println(res)
}
func main() {
per := &Person{name: "huahua"}
user := &User{name: "xiaohua"}
DoSomething(per)
DoSomething(user)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
# 4.1.3 接口断言
- Type Assertion(类型断言)
Type Assertion(中文名叫:类型断言),通过它可以做到以下几件事情:
检查 i 是否为 nil
检查 i 存储的值是否为某个类型
第一种:
t := i.(T)
这个表达式可以断言一个接口对象(i)里不是 nil,并且接口对象(i)存储的值的类型是 T,如果断言成功,就会返回值给 t,如果断言失败,就会触发 panic。
// 示例1
package main
import "fmt"
func main() {
var i interface{} = 10
t1 := i.(int)
fmt.Println(t1)
t2 := i.(string)
fmt.Println(t2)
}
// 第二种
t, ok:= i.(T)
这个表达式也是可以断言一个接口对象(i)里不是 nil,并且接口对象(i)存储的值的类型是 T,如果断言成功,就会返回其类型给 t,并且此时 ok 的值 为 true,表示断言成功。
如果接口值的类型,并不是我们所断言的 T,就会断言失败,但和第一种表达式不同的事,这个不会触发 panic,而是将 ok 的值设为 false ,表示断言失败,此时t 为 T 的零值。
// 示例2
package main
import "fmt"
func main() {
var i interface{} = 10
t1,ok := i.(int)
fmt.Println(t1,ok)
t2,ok := i.(interface{})
fmt.Println(t2,ok)
t3,ok := i.(string)
fmt.Println(t3,ok)
}
"""
打印结果:
10 true
10 true
false // 如果断言失败 则会返回该类型的零值
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
- Type Switch
如果需要区分多种类型,可以使用 type switch 断言,这个将会比一个一个进行类型断言更简单、直接、高效。
package main
import "fmt"
func findType(i interface{}) {
switch x := i.(type) {
case int:
fmt.Println(x,"is int")
case string:
fmt.Println(x,"is string")
case bool:
fmt.Println(x,"is bool")
default:
fmt.Println("未知类型")
}
}
func main() {
findType(10)
findType("nihao")
findType("你好")
findType(10.2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 4.2 面向对象
# 4.2.1 继承
通过结构体的匿名嵌套,继承对应的字段和方法
// 定义person类
type Person struct {
Name string
Email string
Age int
}
// 定义学生类
type Student struct {
Person
StudentId int
}
// 为Person绑定方法
func (p *Person) GetName() {
fmt.Printf("[Person.GetName][name:%s]", p.Name)
}
func main() {
p := Person{
Name: "tchua",
Email: "1@qq.com",
Age: 18,
}
s := Student{
Person: p,
StudentId: 1121,
}
s.GetName()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 4.2.2 多态
# 4.3 错误处理
- errors.New函数:创建错误类型,返回一个error类型
package main
import (
"errors"
"fmt"
"strings"
)
func validataArgs(name string) (ok bool,err error) {
if strings.HasPrefix(name,"mysql") {
return true,nil
} else {
return false,errors.New("name must startwith mysql") // 自定义错误返回类型
}
}
func main() {
s1 := "mysql-ude"
s2 := "redis-aaa"
_,err := validataArgs(s1)
if err != nil {
fmt.Println(err)
}
_,err = validataArgs(s2)
if err != nil {
fmt.Println(err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
- fmt.Errorf方法创建错误
package main
import "fmt"
func div(n1,n2 int) (int,error) {
if n2 == 0 {
return 0,fmt.Errorf("被除数不能为零")
}
return n1 / n2,nil
}
func main() {
fmt.Println(div(4,0))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 4.3.1 复杂错误类型
以os包为例,提供了LinkError、PathError、SyscallReeoe
上述error都是实现了error接口类型错误
可以使用switch err.(type)判断类型
package main
import (
"fmt"
"log"
"os"
)
func main() {
file,err := os.Stat("a.txt")
if err != nil {
switch err.(type) {
case *os.LinkError:
log.Panicln("LinkError")
case *os.PathError:
log.Println("PathError")
case *os.SyscallError:
log.Println("SyscallError")
}
}else {
fmt.Println(file)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 4.3.2 自定义error
自定义结构体,在原始错误信息的基础上再封装自己的错误信息
package main
import (
"errors"
"fmt"
)
type MyError struct {
err error
msg string
}
func (e *MyError) Error() string {
return e.err.Error() + e.msg
}
func main() {
err := errors.New("原始错误")
fmt.Println(err)
newErr := MyError{
err: err,
msg: "这就是自定义的错误",
}
fmt.Println(newErr.Error())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 4.3.3 Error Wrapping 错误嵌套
扩展error信息,不需要再自定义结构体
package main
import (
"errors"
"fmt"
)
func main() {
e := errors.New("原始错误")
w := fmt.Errorf("自定义错误吗?%w",e)
fmt.Println(w)
}
2
3
4
5
6
7
8
9
10
11
12
13
# 4.3.4 panic与recover函数
go语言提供panic和recover函数用于处理运行时错误,当调用panic抛出错误,中断原有的控制流程,常用于不可修复性错误。
recover函数用于终止错误处理流程,仅在defer语句的函数中有效,用于截取错误处理流程,recover只能捕获到最后一个错误
2
panic
panic 中断程序
package main
import "fmt"
func main() {
defer func() {
fmt.Println("defer 01")
}()
panic("出错了")
// 不会执行 panic会中断程序
fmt.Println("我还可以执行吗")
}
2
3
4
5
6
7
8
9
10
11
12
13
- recover
// 没有painc错误时,recover返回nil
package main
import "fmt"
func main() {
defer func() {
fmt.Println(recover()) // nil
}()
fmt.Println(1/0)
}
// 当未发生painc则recover函数得到的结果为painc传递第参数
package main
import "fmt"
func main() {
defer func() {
fmt.Println(recover())
}()
panic("出错了,recover 接收")
}
//
package main
import "fmt"
func callback(p bool) {
if p {
panic("callback panic")
}
fmt.Println("callback running...")
}
func test(p bool) (err error) {
defer func() {
if msg := recover(); msg != nil {
err = fmt.Errorf("%s", msg)
}
}()
callback(p)
return
}
func main() {
fmt.Println(test(true)) // callback panic
fmt.Println(test(false)) //
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 五、标准库
# 5.1 IO基础知识
Go语言中的 IO 操作封装在如下几个包中:
1) io 为 IO 原语提供基本的接口
2) io/ioutil 封装一些实用的 I/O 函数
3) fmt 实现了 I/O 的格式化
4) bufio 实现了带缓冲的 I/O
5) net.Conn 网络的读写
6) os.Stdin, Stdout 系统标准输入输出
7) os.File 系统文件操作
2
3
4
5
6
7
8
# 5.1.1 io 库三个方法之Reader
// 签名方法
type Reader interface {
Read(p []byte) (n int,err error)
}
可见,任何实现了 Read() 函数的对象都可以作为 Reader 来使用
n 读取的字节数 err 任何遇到的错误
2
3
4
5
6
- strings.NewReader
package main
import (
"io"
"log"
"strings"
)
func main() {
s := "cong jint kai shi le 1"
// 定义 一个4字节的读写缓冲区
p := make([]byte,4)
reader := strings.NewReader(s)
// 循环读取 给定的字符串 每次读取4字节
for {
n,err := reader.Read(p)
if err != nil {
// 当碰到 err == EOF时 说明字符串已经读取完毕
if err == io.EOF {
log.Printf("数据已读完 EOF:%d",n)
break
}
log.Printf("未知错误%v",err)
return
}
log.Printf("打印读取到的字节数: %d,打印读取到的内容: %s",n,string(p[:n]))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 5.1.2 bufio
bufio也可以跟Scan函数一样,读取标准输入,也可以作为缓冲IO
package main
import (
"bufio"
"fmt"
"os"
)
var inputReader *bufio.Reader
var input string
var err error
func main() {
inputReader = bufio.NewReader(os.Stdin)
fmt.Println("输入姓名:")
input, err = inputReader.ReadString('\n')
if err == nil {
fmt.Printf("输入的姓名: %s\n", input)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 5.2 os库
# 5.2.1 操作系统相关
// 打印脚本后接的参数 返回一个切片
fmt.Println(os.Args)
// 获取主机名
fmt.Println(os.Hostname())
fmt.Println(os.Getpid())
// 获取全部环境变量
env := os.Environ()
for _,v := range env{
fmt.Println(v)
}
// 获取当前目录
wd,_ := os.Getwd()
fmt.Println(wd)
// 重命名文件
_ = os.Rename("dirs/dir1", "dirs/dir3")
// 创建目录
_ = os.Mkdir("/huahau") // 单目录
_ = os.MkdirAll("/huahua/huahua") // 多级目录 mkdir -p
// 删除目录
_ = os.Remove("dirs/dir2") // 删除但目录
_ = os.RemoveAll("dirs") // 删除多级目录
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 5.2.2 文件操作相关
- 创建写入
// 创建并写入文件内容 创建一个空文件,注意当文件已经存在时,会直接覆盖掉原文件,不会报错
file,_ := os.Create("b.txt")
defer file.Close()
fmt.Println(file.Name())
// 查看文件状态
file_info,_ := file.Stat()
fmt.Println(file_info)
// 写入内容
file.Write([]byte("hello 小哥\n"))
file.WriteString("hello 小哥2\n")
2
3
4
5
6
7
8
9
10
11
12
- 文件追加
func main() {
f,err := os.OpenFile("a.txt",os.O_RDWR|os.O_CREATE|os.O_APPEND, 0644)
defer f.Close()
if err != nil {
fmt.Println(err)
return
}
content := "\n追加内容"
_,_ = f.Write([]byte(content))
}
2
3
4
5
6
7
8
9
10
11
- 查看文件信息
file,_ := os.Open("a.txt")
defer file.Close()
fInfo,_ := file.Stat()
fmt.Println("是否是一个目录",fInfo.IsDir())
fmt.Println("文件修改时间",fInfo.ModTime().String())
fmt.Println("文件名字",fInfo.Name(),file.Name())
fmt.Println("文件大小",fInfo.Size())
fmt.Println("文件权限",fInfo.Mode().String())
2
3
4
5
6
7
8
9
# 5.3 包和工程
# 5.3.1 发布自己的包
1、本地创建一个工程
day06-gomod --> 根目录
hello.go --> 功能文件
package day06_gomod
import "fmt"
func Hello() {
fmt.Println("你好master分支")
}
2、github创建一个项目
https://github.com/tchuaxiaohua/day06-gomod.git
3、提交本地编辑好的代码
cd day06-gomod
go mod init github.com/tchuaxiaohua/day06-gomod
git init
git add .
git commit -m "first commit"
git remote add origin https://github.com/tchuaxiaohua/day06-gomod.git
git push -u origin master
4、tag v1.0.0
git tag v1.0.0
git push origin v1.0.0
5、新建一个工程用于拉取我们开源的库 (GoLand勾选GO MODELE)
hello
cd hello
go mod init
go get gitee.com/tchua/day06-gomod
6、升级小版本至v1.0.1
git checkout -b v1
git add .
git commit -m "xxx"
git tag v1.0.1
git push --tags orgin v1
7、新建工程hello重新获取提交代码
修改go.mod版本号 为v1.0.1
go mod tidy
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 5.4 json
- json.Marshal()
package main
import (
"encoding/json"
"fmt"
)
// 定义结构体标签 json说明该标签只能使用json解析,解析后的字段为对应的标签值
type User struct {
Name string `json:"username"`
Age int `json:"userage"`
Salary int `json:"usersalary"`
}
func main() {
myself := User{
Name: "唐春",
Age: 22,
Salary: 10,
}
// json.Marshal()方法作用就是把结构体转换为json,对应的字段名为标签对应的值
jsdata,err := json.Marshal(myself)
if err != nil {
fmt.Println("格式错误")
} else {
fmt.Printf("User结构体转json:%s\n",jsdata)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
- json.Unmarshl
package main
import (
"encoding/json"
"fmt"
"log"
)
type User struct {
Name string `json:"username"`
Age int `json:"userage"`
Salary int `json:"usersalary"`
}
func main() {
p2Str := `
{
"username":"小花",
"userage":28,
"usersalary":1000
}
`
var u1 User
// json.Unmarshl会将解析后的值存储值一个interface{}类型的值,这里我们把解析到的数据存储到结构体u1中
// 需要注意的是 这里存储对象 需要传对应对象的指针,待反序列化的key需要与结构体标签一致,否则无法正常解析
err := json.Unmarshal([]byte(p2Str),&u1)
if err != nil{
fmt.Printf("json反序列化错误%s",err)
}
log.Printf("反序列化后的内容%+v",u1)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 5.5 yaml
# 5.6 文件操作相关
# 5.6.1 文件读
- os.Open()
os.Open()函数能够打开一个文件,返回一个*File和一个err。对得到的文件实例调用close()方法能够关闭文件。
package main
import (
"fmt"
"io"
"os"
)
func main() {
// 定义一个8字节的读缓冲区,每次读取8字节
var tmp = make([]byte,8)
// 定义空切片
var content []byte
// 读取指定文件,返回文件对象file
file,err := os.Open("./1.txt")
if err != nil {
fmt.Printf("读取文件失败%s",err)
}
defer file.Close()
// 循环读文件内容,因为定义的读缓冲区大小,有可能小于文件内容大小
for i := 0; i <=2 ;i ++ {
// file.Read接收一个读缓冲区tmp切片,并把读取到的内容,写入到该tmp切片,返回n:读取的字节数n<=tmp,err错误
n,err := file.Read(tmp)
fmt.Printf("第%d次读取,n是什么%v,读取内容%s,类型%v\n",i,n,tmp[:n],tmp)
if err != nil {
if err == io.EOF {
fmt.Println("文件读取完毕")
break
}
fmt.Printf("读取文件失败%v",err)
}
// 循环读 每次读取到的内容 都新增到content切片中
content = append(content,tmp[:n]...)
}
fmt.Println(string(content))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
- bufio读取文件
bufio是在file的基础上封装了一层API,支持更多的功能。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
// 读取指定文件,返回文件对象file
file,err := os.Open("./1.txt")
if err != nil {
fmt.Printf("读取文件失败%s",err)
}
defer file.Close()
reader := bufio.NewReader(file)
// 循环读文件内容,因为定义的读缓冲区大小,有可能小于文件内容大小
for {
// ReadString 以什么为分隔符读文件
line,err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
fmt.Println("文件读取完毕")
// 当取到io.EOF时,需要把读取到的内内容打印出来
fmt.Println(line)
break
}
fmt.Printf("读取文件失败%v",err)
}
// 循环读 每次读取到的内容 都新增到content切片中
fmt.Printf("文件内容%s",line)
}
//fmt.Println(string(content))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
- ioutil读取整个文件
io/ioutil包的ReadFile方法能够读取完整的文件,只需要将文件名作为参数传入。
package main
import (
"fmt"
"io/ioutil"
)
// ioutil.ReadFile读取整个文件
func main() {
content, err := ioutil.ReadFile("./1.txt")
if err != nil {
fmt.Println("read file failed, err:", err)
return
}
fmt.Println(string(content))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 5.6.2 文件写入操作
os.OpenFile() 函数能够以指定模式打开文件,从而实现文件写入相关功能。
func OpenFile(name string, flag int, perm FileMode) (*File, error) {
...
}
name:要打开的文件名 flag:打开文件的模式。 模式有以下几种:
2
3
4
| 模式 | 含义 |
|---|---|
os.O_WRONLY | 只写 |
os.O_CREATE | 创建文件 |
os.O_RDONLY | 只读 |
os.O_RDWR | 读写 |
os.O_TRUNC | 清空 |
os.O_APPEND | 追加 |
- Write和WriteString
func main() {
file,err := os.OpenFile("./1.txt",os.O_APPEND|os.O_CREATE|os.O_WRONLY,0644)
if err != nil {
fmt.Printf("文件写入错误",err)
return
}
defer file.Close()
// 写入字节切片数据
file.Write([]byte("【Write写入】nihao 小花"))
// 直接写入字符串数据
file.WriteString("【WriteString写入】nihao 小花")
}
2
3
4
5
6
7
8
9
10
11
12
- bufio.NewWriter
func main() {
file,err := os.OpenFile("./1.txt",os.O_APPEND|os.O_CREATE|os.O_WRONLY,0644)
if err != nil {
fmt.Printf("文件写入错误",err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
// 数据写入缓存
writer.WriteString("你好 小花\n")
}
// 刷新内存数据至文件内
writer.Flush()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- ioutil.WriteFile
func main() {
str := "hello 小哥"
err := ioutil.WriteFile("./xx.txt", []byte(str), 0644)
if err != nil {
fmt.Println("write file failed, err:", err)
return
}
}
2
3
4
5
6
7
8
# 5.7 时间处理
# 5.7.1 时间戳
Unix时间戳(Unix timestamp)定义为从1970年01月01日00时00分00秒(UTC)起至现在经过的总秒数
func main() {
// 获取当前时间
now := time.Now()
// 返回int64位
fmt.Printf("时间戳[秒级]:%v\n",now.Unix())
}
2
3
4
5
6
7
# 5.7.2 时间日期相关
package main
import (
"fmt"
"time"
)
func main() {
// 获取当前时间
now := time.Now()
// 获取年月日
year,month,day := now.Date()
fmt.Printf("当前日期:年: %d, 月: %d, 日: %d\n",year,month,day)
// 年月日 单独获取
fmt.Printf("年:%d\n",now.Year())
fmt.Printf("月:%d\n",now.Month())
fmt.Printf("日:%d\n",now.Day())
// 获取时分秒
hour,min,second := now.Clock()
fmt.Printf("当前时间:[%d:%d:%d]\n",hour,min,second)
// 单独获取 时分秒
fmt.Printf("[直接获取时 %d]\n", now.Hour())
fmt.Printf("[直接获取分 %d]\n", now.Minute())
fmt.Printf("[直接获取秒 %d]\n", now.Second())
// 星期几
fmt.Printf("星期几:%d\n",now.Weekday())
// 时区
zone, offset := now.Zone()
fmt.Printf("[直接获取时区 %v,和东utc时区差 几个小时: %d]\n", zone, offset/3600)
fmt.Printf("[今天是 %d年 中的第 %d天]\n", now.Year(), now.YearDay())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 5.7.3 格式化时间
Go 语言提供了时间类型格式化函数 Format(), 2006-01-02 15:04:05,也很好记忆(2006 1 2 3 4 5)
- 时间对象转字符串
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
// 当前时间
fmt.Printf("当前时间:%v\n",now.Format("2006-01-02 15:04:05"))
fmt.Printf("只格式化日期:%v",now.Format("2006-01-02"))
}
2
3
4
5
6
7
8
9
10
11
12
13
- 时间戳与日期字符串相互转化
要先将时间戳转成 time.Time 类型再格式化成日期格式
package main
import (
"fmt"
"time"
)
func main() {
// 获取当前时间戳
now := time.Now().Unix()
// 格式化时间模板
layout := "2006-01-02 15:04:05"
// 构造时间对象
t := time.Unix(now,0)
fmt.Printf(t.Format(layout))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 日期字符串转时间戳
解析时常用 time.ParseInLocation(),可以指定时区
tStr := "2021-07-17 16:52:59"
layout := "2006-01-02 15:04:05"
t1, _ := time.ParseInLocation(layout, tStr, time.Local)
t2, _ := time.ParseInLocation(layout, tStr, time.UTC)
log.Printf("[ %s的 CST时区的时间戳为 :%d]", tStr, t1.Unix())
log.Printf("[ %s的 UTC时区的时间戳为 :%d]", tStr, t2.Unix())
log.Printf("[UTC - CST =%d 小时]", (t2.Unix()-t1.Unix())/3600)
2
3
4
5
6
7
8
- 时间差
package main
import (
"fmt"
"time"
)
var layout = "2006-01-02 15:04:05"
// 函数 时间格式化
func tTostr(t time.Time) string {
return time.Unix(t.Unix(), 0).Format(layout)
}
func main() {
now := time.Now()
// 当前时间
fmt.Printf("当前时间:%s\n",now.Format(layout))
// 1小时1分1秒后
t1,_ := time.ParseDuration("1h1m1s")
m2 := now.Add(t1)
fmt.Printf("1小时1分1秒后时间为:%s\n",m2.Format(layout))
// sub计算两个时间差
sub1 := now.Sub(m2)
fmt.Printf("当前时间与1小时1分1秒后时间差:%s",sub1)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 5.7.4 Timer 和 Ticker
func tickDemo() {
ticker := time.Tick(time.Second) //定义一个1秒间隔的定时器
for i := range ticker {
fmt.Println(i)//每秒都会执行的任务
}
}
2
3
4
5
6
# 5.8 flag
实现了命令行参数的解析,flag包使得开发命令行工具更为简单。
package main
import (
"flag"
"fmt"
)
var (
port int
passwd string
help bool
)
func main() {
// 指定变量与命令行参数关系
flag.IntVar(&port,"-P",22,"port")
flag.StringVar(&passwd,"-p","","password")
flag.BoolVar(&help,"-h",false,"help")
if help {
// flag 默认帮助信息
flag.Usage()
}
// 解析上面命令行参数
flag.Parse()
// 未指定 参数名称的参数列表
fmt.Println(flag.Args())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 六、反射
# 6.1 为什么需要反射
有时候我们需要编写一个函数能够处理一类并不满足普通公共接口的类型的值,也可能是因为它们并没有确定的表示方式,或者是在我们设计该函数的时候这些类型可能还不存在。
# 6.2 使用反射获取变量内部的信息
var s1 string="nihao"
// 获取变量类型
s := reflect.TypeOf(s1)
fmt.Println(s)
// 获取变量值 如果为空 返回该类型的零值
s2 := reflect.ValueOf(s1)
fmt.Println(s2)
"""
函数 reflect.TypeOf 接受任意的 interface{} 类型,并以 reflect.Type 形式返回其动态类型
函数 reflect.ValueOf 接受任意的 interface{} 类型,并返回一个装载着其动态值的 reflect.Value
"""
2
3
4
5
6
7
8
9
10
11
12
# 6.3 自定义struct的反射
package main
import (
"fmt"
"log"
"reflect"
)
// 定义结构体
type Person struct {
Name string
Age int
}
// 定义结构体
type Student struct {
Person
StudentId int
SchoolName string
IsBaoSong bool
Bobbies []string
Labels map[string]interface{}
}
// 结构体方法
func (s *Student) GoHome() {
log.Printf("回家了%d",s.StudentId)
}
func (s Student) GOSchool() {
log.Printf("去上学%d",s.StudentId)
}
func (s Student) baosong() {
log.Printf("竞赛保送%d",s.StudentId)
}
func main() {
s := Student{
Person: Person{Name: "tchua",Age: 23},
StudentId: 1208,
SchoolName: "beijing",
IsBaoSong: false,
Bobbies: []string{"篮球","足球"},
Labels: map[string]interface{}{"班级":1204,},
}
// 获取目标对象
r := reflect.TypeOf(s)
fmt.Println(r)
log.Printf("成员对象个数%d",r.NumField())
// 获取目标对象的值
r1 := reflect.ValueOf(s)
fmt.Println(r1)
// 遍历成员变量
for i := 0;i < r.NumField(); i ++ {
// 字段名
filed := r.Field(i)
// 对应的值
value := r1.Field(i).Interface()
if filed.Anonymous {
log.Printf("[匿名字段][第:%d个字段][字段名:%s][字段的类型:%v][字段的值:%v]", i+1, filed.Name, filed.Type, value)
} else {
log.Printf("[命名字段][第:%d个字段][字段名:%s][字段的类型:%v][字段的值:%v]", i+1, filed.Name, filed.Type, value)
}
}
// 遍历结构体绑定方法
for i := 0;i < r.NumMethod(); i ++ {
m := r.Method(i)
log.Printf("[第%d个方法][方法名称:%s][方法类型:%v]",i+1,m.Name,m.Type)
}
}
"""
main.Student
2021/07/19 16:38:02 成员对象个数6
2021/07/19 16:38:02 结构体方法个数1
2021/07/19 16:38:02 [匿名字段][第:1个字段][字段名:Person][字段的类型:main.Person][字段的值:{tchua 23}]
2021/07/19 16:38:02 [命名字段][第:2个字段][字段名:StudentId][字段的类型:int][字段的值:1208]
2021/07/19 16:38:02 [命名字段][第:3个字段][字段名:SchoolName][字段的类型:string][字段的值:beijing]
2021/07/19 16:38:02 [命名字段][第:4个字段][字段名:IsBaoSong][字段的类型:bool][字段的值:false]
2021/07/19 16:38:02 [命名字段][第:5个字段][字段名:Bobbies][字段的类型:[]string][字段的值:[篮球 足球]]
2021/07/19 16:38:02 [命名字段][第:6个字段][字段名:Labels][字段的类型:map[string]interface {}][字段的值:map[班级:1204]]
2021/07/19 16:38:02 [第1个方法][方法名称:GOSchool][方法类型:func(main.Student)]
{{tchua 23} 1208 beijing false [篮球 足球] map[班级:1204]}
"""
注意:
结构体方法名小写是不会panic,反射时也不会被查看到,指针方法是不能被反射查看到的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
# 6.3.1 结构体反射方法总结
| 方法 | 说明 |
|---|---|
| Field(i int) StructField | 根据索引,返回索引对应的结构体字段的信息。 |
| NumField() int | 返回结构体成员字段数量。 |
| FieldByName(name string) (StructField, bool) | 根据给定字符串返回字符串对应的结构体字段的信息。 |
| FieldByIndex(index []int) StructField | 多层成员访问时,根据 []int 提供的每个结构体的字段索引,返回字段的信息。 |
| FieldByNameFunc(match func(string) bool) (StructField,bool) | 根据传入的匹配函数匹配需要的字段。 |
| NumMethod() int | 返回该类型的方法集中方法的数目 |
| Method(int) Method | 返回该类型方法集中的第i个方法 |
| MethodByName(string)(Method, bool) | 根据方法名返回该类型方法集中的方法 |
# 6.3.2 反射在不同类型中的使用
Slice和数组: 两种的处理逻辑是一样的。Len方法返回slice或数组值中的元素个数,Index(i)获得索引i对应的元素,返回的也是一个reflect.Value;如果索引i超出范围的话将导致panic异常,这与数组或slice类型内建的len(a)和a[i]操作类似。display针对序列中的每个元素递归调用自身处理,我们通过在递归处理时向path附加“[i]”来表示访问路径。
虽然reflect.Value类型带有很多方法,但是只有少数的方法能对任意值都安全调用。例如,Index方法只能对Slice、数组或字符串类型的值调用,如果对其它类型调用则会导致panic异常。
结构体: NumField方法报告结构体中成员的数量,Field(i)以reflect.Value类型返回第i个成员的值。成员列表也包括通过匿名字段提升上来的成员。为了在path添加“.f”来表示成员路径,我们必须获得结构体对应的reflect.Type类型信息,然后访问结构体第i个成员的名字。
Maps: MapKeys方法返回一个reflect.Value类型的slice,每一个元素对应map的一个key。和往常一样,遍历map时顺序是随机的。MapIndex(key)返回map中key对应的value。我们向path添加“[key]”来表示访问路径。(我们这里有一个未完成的工作。其实map的key的类型并不局限于formatAtom能完美处理的类型;数组、结构体和接口都可以作为map的key。针对这种类型,完善key的显示信息是练习12.1的任务。)
指针: Elem方法返回指针指向的变量,依然是reflect.Value类型。即使指针是nil,这个操作也是安全的,在这种情况下指针是Invalid类型,但是我们可以用IsNil方法来显式地测试一个空指针,这样我们可以打印更合适的信息。我们在path前面添加“*”,并用括弧包含以避免歧义。
接口: 再一次,我们使用IsNil方法来测试接口是否是nil,如果不是,我们可以调用v.Elem()来获取接口对应的动态值,并且打印对应的类型和值。
2
3
4
5
6
7
8
9
10
11
# 6.4 反射修改值
var num float64=3.12
log.Printf("原始值%f",num)
// 通过reflect.ValueOf获取num中的value
pointer := reflect.ValueOf(&num)
// Elem获取指针指向的变量
newValue := pointer.Elem()
newValue.SetFloat(6.66)
log.Printf("新值为%f",num)
2
3
4
5
6
7
8
9
10
# 6.5 反射调用方法
package main
import (
"log"
"reflect"
)
type Person struct {
Name string
Age int
Gender string
}
func (p Person) Say(name string,age int) {
log.Printf("调用的是带参数的方法【args.name:%s】【args.age:%d】[p.name:%s][p.Age:%d]",
name,
age,
p.Name,
p.Age)
}
func (p Person) Hello() {
log.Printf("调用的是不带参数的方法")
}
func main() {
p := Person{
Name: "小花",
Age: 22,
Gender: "男",
}
// 首先通过reflect.ValueOf(p1)获取 得到反射类型对象
getValue := reflect.ValueOf(p)
// 带参数调用 通过MethodByName注册方法
methodValue := getValue.MethodByName("Say")
// 参数是reflect.Value的切片 []reflect.Value 调用的方法的参数,可以为空,根据方法的实际参数来定义
args := []reflect.Value{reflect.ValueOf("李逵"),reflect.ValueOf(30)}
methodValue.Call(args)
// 不带参数的调用 通过MethodByName注册方法 需要指定正确的方法名,MethodByName返回一个函数值对应的reflect.Value方法的名字
methodValue = getValue.MethodByName("Hello")
args = make([]reflect.Value,0)
methodValue.Call(args)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 6.6 获取结构体字段标签
# 七、数据结构
# 7.1 栈
先进后出
# 八、补充
# 8.1 锁
# 8.1.1 互斥锁(sync.mutex )
- 获取到锁的任务,阻塞其它任务
- 也就是同一时间只能有一个任务获取到锁
var HcMurex sync.Mutex
func runMutex(id int) {
log.Printf("[任务id:%d][尝试获取锁]", id)
HcMurex.Lock()
log.Printf("[任务id:%d][获取到了锁][开始干活:睡眠10s]", id)
time.Sleep(10 * time.Second)
HcMurex.Unlock()
log.Printf("[任务id:%d][干完活了 释放锁]", id)
}
func runHcLock() {
go runMutex(1)
go runMutex(2)
go runMutex(3)
}
func main() {
runHcLock()
time.Sleep(40 * time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 8.1.2 读写锁(sync.rwmutex)
- 写锁阻塞所有锁(所有读锁和写锁) ,目的是修改时其他人不要读取,也不要修改
- 读锁阻塞写锁 ,读锁可以同时施加多个 。目的 不要让修改数据影响我的读取结果
- 同时多个读任务, 可以施加多个读锁,阻塞写锁
- 同时多个写任务 ,只可以施加一个写锁,阻塞其他所有锁 ,退化成互斥锁
- 读写混合:若有写锁,等待释放后能施加 读或写
- 读写混合:若有读锁,只能再施加读锁,阻塞写锁
var rwMute sync.RWMutex
// 读任务函数
func runReadLock(id int) {
log.Printf("[读任务id:%d][尝试获取读锁]", id)
rwMute.RLock()
log.Printf("[读任务id:%d][获取到了读锁][开始干活:睡眠10s]", id)
time.Sleep(10 * time.Second)
rwMute.RUnlock()
log.Printf("[读任务id:%d][干完活了 释放读锁]", id)
}
// 写任务函数
func runWriteLock(id int) {
log.Printf("[写任务id:%d][尝试获取写锁]", id)
rwMute.Lock()
log.Printf("[写任务id:%d][获取到了写锁][开始干活:睡眠10s]", id)
time.Sleep(10 * time.Second)
rwMute.Unlock()
log.Printf("[写任务id:%d][干完活了 释放写锁]", id)
}
// 只执行写任务
func allWriteWorks(){
for i := 1; i < 6; i++ {
go runWriteLock(i)
}
}
// 只执行读任务
func allReadWorks(){
for i := 1;i < 6; i ++ {
go runReadLock(i)
}
}
// 先执行写 再执行读任务
func firstWrite(){
go runWriteLock(1)
time.Sleep(1*time.Second)
go runReadLock(2)
go runReadLock(3)
go runReadLock(4)
}
// 先执行读 再执行写任务
func firstRead(){
go runReadLock(1)
go runReadLock(2)
go runReadLock(3)
go runReadLock(4)
time.Sleep(1*time.Second)
go runWriteLock(5)
}
func main() {
// 互斥锁任务
// runHcLock()
// 读写锁 写锁执行效果
// allWriteWorks()
// 读写锁 读写执行效果
// allReadWorks()
// 读写锁 读写锁混合使用 先执行读
// firstRead()
// 读写锁 读写锁混合使用 先执行写
firstWrite()
time.Sleep(60 * time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72