 Namespace和Cgroups
Namespace和Cgroups
# 一、Namespace
# 1.1 介绍
Linux Namespace提供了一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的Namespace中,来实现资源隔离的目的。不同Namespace的程序,可以享有一份独立的系统资源。目前Linux中提供了六类系统资源的隔离机制,分别是:
| namespace | 系统调用参数 | 隔离内容 | 内核版本 |
|---|---|---|---|
| Mount | CLONE_NEWNS | 文件系统挂载点 | |
| UTS | CLONE_NEWUTS | 主机名和域名信息 | |
| IPC | CLONE_NEWIPC | 进程间通信 | |
| PID | CLONE_NEWPID | 进程的ID | |
| Network | CLONE_NEWNET | 网络资源 | |
| User | CLONE_NEWUSER | 用户和用户组的ID | |
| Cgroup | CLONE_NEWGROUP | cgroup的根目录 |
由于namespace机制的存在,可以把系统分为四层:
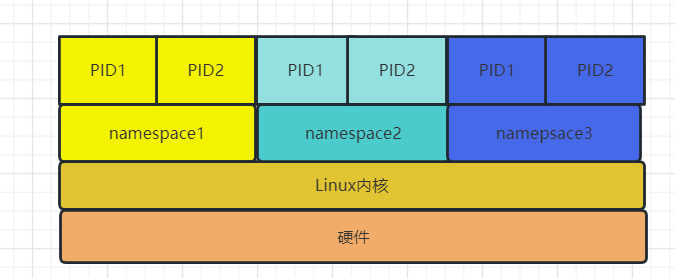
- 每个namespace下的资源对其它namespace不可见
- PID、IPC等系统资源不再属于全局性,隶属于某一个特定namespace
- 对于用户只能看到属于自己namespace下的资源
# 1.2 命令
- 查看当前进程所属namespace
# 查看当前进程所属namespace
[root@localhost ~]# ll /proc/$$/ns
total 0
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Feb 14 10:13 uts -> uts:[4026531838]
2
3
4
5
6
7
8
9
- 看当前系统namespace
# 用于查看当前系统namespace
[root@localhost ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531837 user 175 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531838 uts 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531839 ipc 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531840 mnt 170 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531856 mnt 1 18 root kdevtmpfs
4026531956 net 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026532431 mnt 1 792 root /usr/sbin/NetworkManager --no-daemon
2
3
4
5
6
7
8
9
10
11
解读
- namespace文件都是链接文件,格式为:
xx:[inode id],xx其实就是namespace类型,inode id可以理解为namespace的ID,如果两个进程的某个namespace对应的ID一样,则说明这些资源是共享的,也就是说再统一个namespace中 - 对于同一类型namespace,系统中会同同时存在多个namespace,属于这些namespace下的资源是互相隔离的
# 1.3 创建
# 创建命名空间并运行bash进程
# ## 创建命名空间 使用自己的pid 挂载点
[root@localhost ~]# unshare --fork --pid --mount-proc bash
# ## 查看当前namespace
[root@localhost ~]# ll /proc/$$/ns
total 0
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 mnt -> mnt:[4026532525]
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 pid -> pid:[4026532526]
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Feb 14 15:25 uts -> uts:[4026531838]
[root@localhost ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 15:25 pts/0 00:00:00 bash
root 12 1 0 15:25 pts/0 00:00:00 ps -ef
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
说明
- 通过与宿主机对比可以看出,user、ipc、net都是一样的,说明这些namespace下的资源是共享的
- 在新的命名空间下执行
ps -ef只能看到两个进程(打开新的窗口,查看是看不到这2个进程的) - mnt、pid与宿主机不同,说明pid、mnt与其它是隔离的
# 1.4 与docker的关系
- 查看系统现有namespace
# 系统初始化
[root@localhost ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531837 user 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531838 uts 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531839 ipc 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531840 mnt 170 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531856 mnt 1 18 root kdevtmpfs
4026531956 net 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026532431 mnt 1 792 root /usr/sbin/NetworkManager --no-daemon
2
3
4
5
6
7
8
9
10
11
12
- 启动容器再次查看
# 启动nginx容器
[root@localhost ~]# docker run --rm -it -d nginx
Unable to find image 'nginx:latest' locally
latest: Pulling from library/nginx
bb263680fed1: Pull complete
258f176fd226: Pull complete
a0bc35e70773: Pull complete
077b9569ff86: Pull complete
3082a16f3b61: Pull complete
7e9b29976cce: Pull complete
Digest: sha256:6650513efd1d27c1f8a5351cbd33edf85cc7e0d9d0fcb4ffb23d8fa89b601ba8
Status: Downloaded newer image for nginx:latest
e5cef4684a8c62c7e699acc57c37d93ef37f0e8ad1b86dd3509193ac87d28d21
# 查看运行状态
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e5cef4684a8c nginx "/docker-entrypoint.…" 4 seconds ago Up 2 seconds 80/tcp exciting_boyd
# 查看目前命名空间
[root@localhost ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 174 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531837 user 177 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531838 uts 174 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531839 ipc 174 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531840 mnt 172 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026531856 mnt 1 18 root kdevtmpfs
4026531956 net 174 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 22
4026532431 mnt 1 792 root /usr/sbin/NetworkManager --no-daemon
4026532437 mnt 3 2286 root nginx: master process nginx -g daemon off
4026532438 uts 3 2286 root nginx: master process nginx -g daemon off
4026532439 ipc 3 2286 root nginx: master process nginx -g daemon off
4026532440 pid 3 2286 root nginx: master process nginx -g daemon off
4026532442 net 3 2286 root nginx: master process nginx -g daemon off
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
说明
nginx容器启动之后,我们再次查看namespace可以看到,多出了nginx进程创建的5种命名空间,这是docker默认帮我们创建。通过该对比可以看到mnt、uts、ipc、pid、net这5种namespace资源跟系统以及其它进程是隔离的。这也证明了Docker容器的底层还是基于系统级别namespace进行资源隔离。
# 二、Cgroups
# 2.1 介绍
控制组 (cgroup) 是 Linux 内核的一个特性,用于限制、记录和隔离一组进程的资源使用(CPU、内存、磁盘 I/O、网络等)。
# 2.2 概念
任务(Tasks):就是系统的一个进程。
控制组(Control Group):一组按照某种标准划分的进程,其表示了某进程组,Cgroups中的资源控制都是以控制组为单位实现,一个进程可以加入到某个控制组。而资源的限制是定义在这个组上,简单点说,cgroup的呈现就是一个目录带一系列的可配置文件。
层级(Hierarchy):控制组可以组织成hierarchical的形式,既一颗控制组的树(目录结构)。控制组树上的子节点继承父结点的属性。简单点说,hierarchy就是在一个或多个子系统上的cgroups目录树。
子系统(Subsystem):一个子系统就是一个资源控制器,比如CPU子系统就是控制CPU时间分配的一个控制器。子系统必须附加到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。Cgroup的子系统可以有很多,也在不断增加中。
2
3
4
5
6
7
# 2.3 子资源系统
以下为内核3.10+支持的子系统(可以通过 ls /sys/fs/cgroup 查看到):
- blkio : 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu : 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct : 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset : 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices : 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer: 这个子系统挂起或者恢复 cgroup 中的任务。
- memory:这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls : 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio: 这个子系统用来设计网络流量的优先级
- hugetlb: 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
# 2.4 查看cgroup挂载点
[root@localhost ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
2
3
4
5
6
7
8
9
10
11
12
注意
如果使用上面命令查询不到cgroup挂载目录,可以通过以下命令实现挂载:
mount -t cgroup -o cpu,cpuset,memory cpu_and_mem /cgroup/cpu_and_mem
以上目录都可以是限制的对象,也就是概念中的各个子系统。每个 cgroup 目录下面都会有描述该 cgroup 的文件,除了每个 cgroup 独特的资源控制文件,还有一些通用的文件,例如查看这里的CPU限制目录:
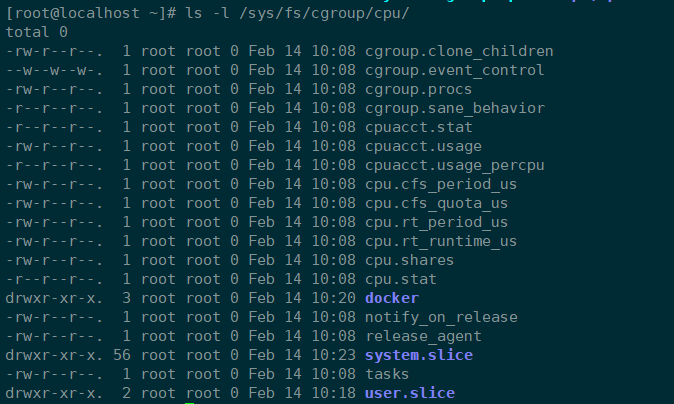
笔记
tasks:当前 cgroup 包含的任务(task)pid 列表,把某个进程的 pid 添加到这个文件中就等于把进程移到该 cgroupcgroup.procs:当前 cgroup 中包含的 thread group 列表,使用逻辑和tasks相同notify_on_release:0 或者 1,是否在 cgroup 销毁的时候执行 notify。如果为 1,那么当这个 cgroup 最后一个任务离开时(退出或者迁移到其他 cgroup),并且最后一个子 cgroup 被删除时,系统会执行release_agent中指定的命令release_agent:需要执行的命令
# 2.5 实战
- CPU限制
创建cgroup
# 当在对应子资源中创建目录后,会自动创建对应的限制配置文件
[root@localhost ~]# mkdir /sys/fs/cgroup/cpu/cpu_limit
[root@localhost ~]# ll !$
ll /sys/fs/cgroup/cpu/cpu_limit
total 0
-rw-r--r--. 1 root root 0 Feb 15 13:54 cgroup.clone_children
--w--w--w-. 1 root root 0 Feb 15 13:54 cgroup.event_control
-rw-r--r--. 1 root root 0 Feb 15 13:54 cgroup.procs
-r--r--r--. 1 root root 0 Feb 15 13:54 cpuacct.stat
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpuacct.usage
-r--r--r--. 1 root root 0 Feb 15 13:54 cpuacct.usage_percpu
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpu.rt_period_us
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 Feb 15 13:54 cpu.shares
-r--r--r--. 1 root root 0 Feb 15 13:54 cpu.stat
-rw-r--r--. 1 root root 0 Feb 15 13:54 notify_on_release
-rw-r--r--. 1 root root 0 Feb 15 13:54 tasks
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
参数
- cpu.cfs_quota_us: 配置当前cgroup在设置的周期长度内所能使用的CPU时间数,默认-1,表示不限制
- cpu.cfs_period_us: 配置时间周期长度,默认100000us
压测CPU
cat /dev/urandom | gzip -9 > /dev/null
或者
while : ; do : ; done &
2
3
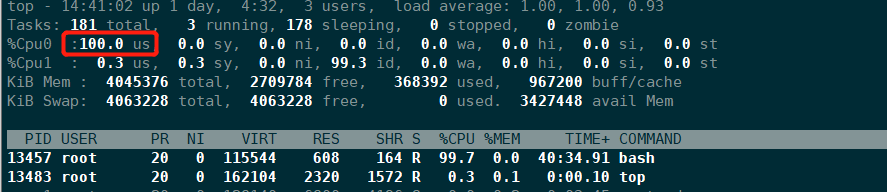
限制CPU
# 限制使用1个CPU的20%(每50ms能使用10ms的CPU时间,即使用一个CPU核心的20%)
[root@localhost ~]# echo 10000 > /sys/fs/cgroup/cpu/cpu_limit/cpu.cfs_quota_us /* quota = 10ms */
[root@localhost ~]# echo 50000 > /sys/fs/cgroup/cpu/cpu_limit/cpu.cfs_period_us /* period = 50ms */
# 进程写入tasks文件
[root@localhost ~]# echo 13457 > /sys/fs/cgroup/cpu/cpu_limit/tasks
# 可以看到限制后,使用率降到20%,说明限制已经生效
2
3
4
5
6
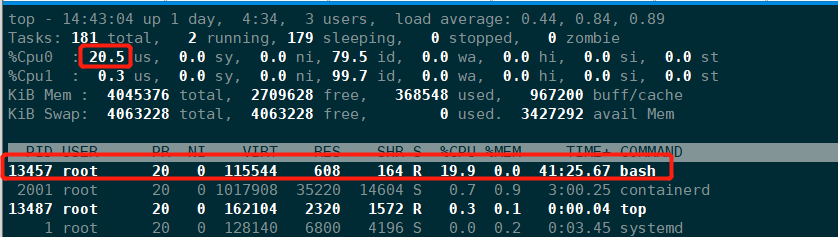
小知识
1.限制只能使用1个CPU(每250ms能使用250ms的CPU时间)
# echo 250000 > cpu.cfs_quota_us /* quota = 250ms */
# echo 250000 > cpu.cfs_period_us /* period = 250ms */
2.限制使用2个CPU(内核)(每500ms能使用1000ms的CPU时间,即使用两个内核)
# echo 1000000 > cpu.cfs_quota_us /* quota = 1000ms */
# echo 500000 > cpu.cfs_period_us /* period = 500ms */
3.限制使用1个CPU的20%(每50ms能使用10ms的CPU时间,即使用一个CPU核心的20%)
# echo 10000 > cpu.cfs_quota_us /* quota = 10ms */
# echo 50000 > cpu.cfs_period_us /* period = 50ms */
2
3
4
5
6
7
8
9
10
11
# 2.6 Docker中资源限制
介绍
上面实验了针对cpu的限制,其实其它资源memory,blkio等都是类似做法,了解linux系统Cgroup限制后,Docker资源限制其实也是一样,默认情况下,docker会对应的限制子系统下创建一个docker目录。
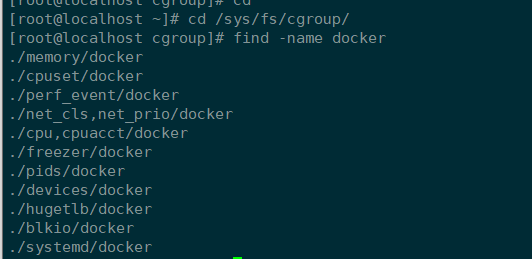
当我们在系统中起到一个容器后,无论是否有对资源有限制,都在在cgroup子系统docker目录下创建一个以容器ID命名的目录,并且也会自动创建限制资源的一些文件,此目录是专门用来限制这一个容器。
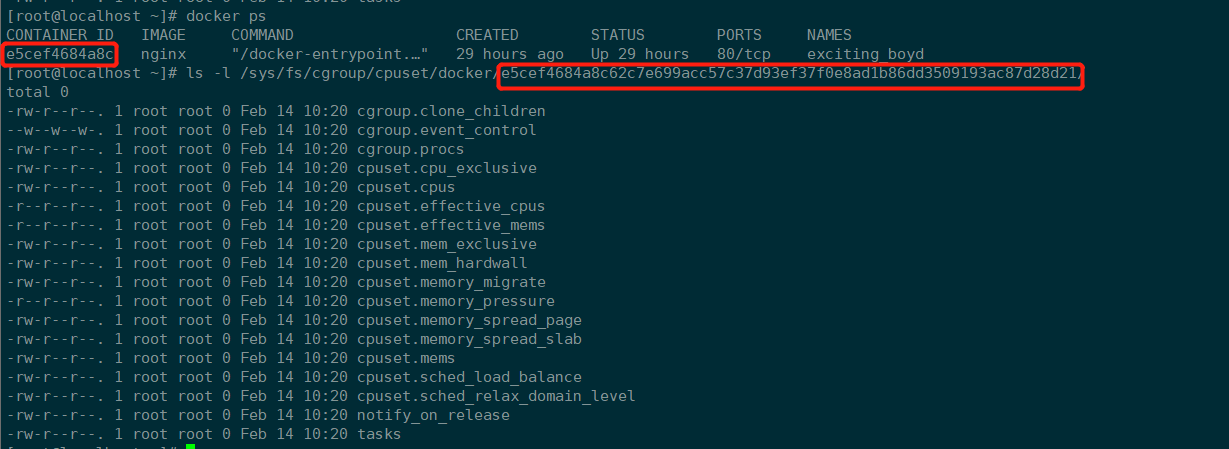
CPU限制
默认情况下,Docker容器启动后,使用资源是不受限制的,宿主机有多少资源,容器就可以使用多少资源。
- 限制cpu配额
# 限制只能使用一个cpu
# ## 相当于使用--cpus=2参数
docker run -d --cpu-period=100000 --cpu-quota=100000 --name nginx-cpu1 nginx:latest
# ## 进入容器进行压测
[root@localhost ~]# docker exec -it nginx-cpu1 /bin/bash
root@cf4916c6131a:/# while : ; do : ; done &
# ## 查看容器对应宿主机PID
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cf4916c6131a nginx:latest "/docker-entrypoint.…" 3 minutes ago Up 3 minutes 80/tcp nginx-cpu1
# ## 13925 及为容器中压测bash映射至宿主机ID
[root@localhost ~]# docker top cf4
UID PID PPID C STIME TTY TIME CMD
root 13679 13659 0 15:19 ? 00:00:00 nginx: master process nginx -g daemon off;
101 13728 13679 0 15:19 ? 00:00:00 nginx: worker process
101 13729 13679 0 15:19 ? 00:00:00 nginx: worker process
root 13872 13659 0 15:19 pts/0 00:00:00 /bin/bash
root 13925 13872 99 15:20 pts/0 00:02:45 /bin/bash
# 查看Cgroup限制文件配置
[root@localhost ~]# cat /sys/fs/cgroup/cpu/docker/cf4916c6131a50a2fd4a41d11f6bd6e8e22fc78132ec9740798586e405b70160/cpu.cfs_period_us
100000
[root@localhost ~]# cat /sys/fs/cgroup/cpu/docker/cf4916c6131a50a2fd4a41d11f6bd6e8e22fc78132ec9740798586e405b70160/cpu.cfs_quota_us
100000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26

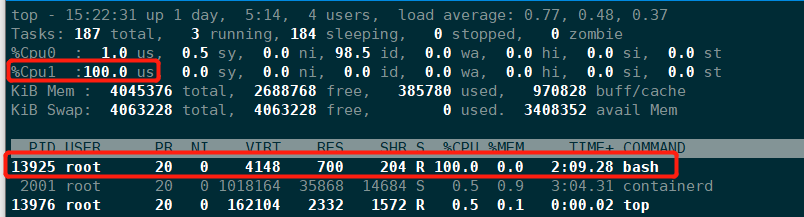

限制使用固定CPU
# 限制使用cpu0
docker run -d --cpuset-cpus=0 --name nginx-cpu2 nginx:latest
# 进入容器压测
[root@localhost ~]# docker exec -it a37380b3664c /bin/bash
root@a37380b3664c:/# while : ; do : ; done &
# 查看压测进程ID
[root@localhost ~]# docker top a37380b3664c
UID PID PPID C STIME TTY TIME CMD
root 14132 14110 0 15:33 ? 00:00:00 nginx: master process nginx -g daemon off;
101 14180 14132 0 15:33 ? 00:00:00 nginx: worker process
101 14181 14132 0 15:33 ? 00:00:00 nginx: worker process
root 14243 14110 99 15:33 ? 00:00:54 /bin/bash
# 查看Cgroup限制文件配置
[root@localhost ~]# cat /sys/fs/cgroup/cpuset/docker/a37380b3664c6e3657555c97e882a3c68e0d78bacc261db1607128a34d876b14/cpuset.cpus
0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
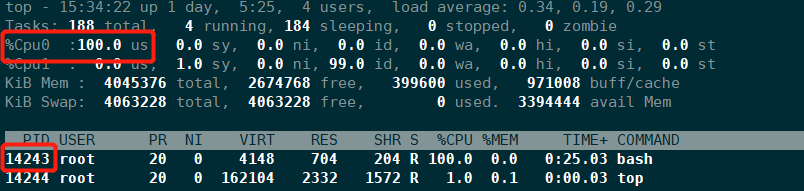
总结
通过上面测试可以看出,当我们使用参数限制容器使用宿主机资源时,会在对应的子系统限制目录文件中,写入对应的参数值,这说明Docker的资源限制原理就是根据系统Cgroup进程处理。
# 三、总结
Namespace 和 cgroup 是容器和现代应用的构建模块。当我们将应用重构为更现代的架构后,深入了解它们的工作方式非常重要。
Namespace 支持系统资源隔离,而 cgroup 则支持对这些资源进行精细的控制和限制。
容器并非 namespace 和 cgroup 的唯一用例。namespace 和 cgroup 接口内置于 Linux 内核中,这意味着其他应用也可以使用它们来提供隔离和资源限制。
2
3