 Jenkins之pipline语法
Jenkins之pipline语法
# 一、前言
前面我们在pipline初始中以一个简单的示例,介绍了Jenkins中pipline的简单用法,本文开始将以官方文档基础介绍下流水线所涉及到的相关参数,当然也不会全部都讲解,只是会对使用频率较高的进行说明,最后也会给出一个完整示例,仅供参考。
# 二、pipline 语法
这里老规矩先给出一个基本的示例,包含了日常工作中大部分的功能,此示例我是借助
ChatGPT生成的一个demo。
pipeline {
agent {
// 指定运行流水线的代理,可以是特定的节点或者是Docker等
label 'my-agent'
}
tools {
// 安装和使用Maven
maven 'Maven-3.8.2'
// 安装和使用JDK
jdk 'JDK-11'
}
options {
// 全局选项配置
skipDefaultCheckout() // 禁用默认的代码检出
timeout(time: 1, unit: 'HOURS') // 设置流水线超时时间为1小时
buildDiscarder(logRotator(numToKeepStr: '10')) // 保留最近10个构建日志
timestamps() // 时间戳
}
triggers {
// 触发器配置,例如定时触发、SCM变更等
cron('H */4 * * 1-5') // 每4小时触发一次
pollSCM('*/15 * * * *') // 每15分钟轮询一次SCM变更
upstream('other-pipeline', 'SUCCESS') // 当名为 'other-pipeline' 的流水线成功执行时触发
}
parameters {
// 流水线参数定义
string(name: 'PARAM', defaultValue: 'default_value', description: 'This is a parameter')
booleanParam(name: 'FLAG', defaultValue: true, description: 'This is a boolean parameter')
choice(name: 'CHOICE', choices: ['Option 1', 'Option 2', 'Option 3'], description: 'Select an option')
}
environment {
// 环境变量定义
MY_VARIABLE = "Hello, World!"
}
stages {
stage('Checkout') {
steps {
// 检出代码到工作空间
checkout scm
}
}
stage('Build') {
agent {
// 针对特定阶段的代理配置
label 'build-agent'
}
steps {
// 构建步骤
sh 'mvn clean install'
}
}
stage('Test') {
parallel {
stage('Unit Tests') {
steps {
// 单元测试步骤
sh 'mvn test'
}
}
stage('Integration Tests') {
steps {
// 集成测试步骤
sh 'mvn integration-test'
}
}
}
}
stage('Deploy') {
when {
// 根据条件来控制执行阶段
branch 'master'
environment name: 'DEPLOY_FLAG', value: 'true'
}
steps {
// 部署步骤
sh 'mvn deploy'
}
}
}
post {
always {
// 总是执行的操作
archiveArtifacts 'target/*.jar' // 存档构建产物
}
success {
// 流水线成功时执行的操作
script {
// 执行更复杂的Groovy脚本
def version = getVersionFromPom() // 从POM文件中获取版本号
updateArtifactVersion(version) // 更新其他系统中的版本号
}
}
failure {
// 流水线失败时执行的操作
sendNotification('Pipeline Failed', 'The pipeline execution has failed.')
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# 2.1 pipline
语法标识,流水线顶层关键字之一,pipeline关键字用于创建一个Pipeline流水线的基本框架,其中包含了一系列阶段(stage)和后续操作(post)。
# 2.2 agent
定义任务执行节点,可以是Jenkins的节点(如master节点或具体的agent节点),也可以是Docker容器、Kubernetes Pod等。
- any,任意节点
pipeline {
agent any
stages {
// 阶段定义
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
- label,指定Jenkins节点构建
pipeline {
agent {
label 'my-agent'
}
stages {
// 阶段定义
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
- docker,指定Docker容器运行
流水线将在基于
maven:3.8.2镜像的Docker容器中运行。-v /path/to/workspace:/workspace参数将主机上的工作空间目录挂载到Docker容器中,以便在容器中访问工作空间。
pipeline {
agent {
docker {
image 'maven:3.8.2'
args '-v /path/to/workspace:/workspace'
}
}
stages {
// 阶段定义
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- kubertenes,指定k8s运行
流水线将在基于自定义Kubernetes Pod定义的Pod中运行。
defaultContainer 'jnlp'指定了Jenkins JNLP代理容器作为主要容器,并在该Pod中的containers部分添加了一个名为maven的容器,使用maven:3.8.2镜像,并执行sleep infinity命令以保持容器的运行。
pipeline {
agent {
kubernetes {
// Jenkins连接的k8s集群设置的别名
// Jenkins不属于集群外 才会使用到该配置
cloud 'kubernetes'
// Jenkins容器模版,用来与主节点建立通信
defaultContainer 'jnlp'
// Jenkins slave 动态命名
label "jnlp-slave-${BUILD_TAG}"
//设置为2 意味着当一个构建执行器(jenkins slave)在空闲状态超过2分钟时,Jenkins 将会终止与该节点关联的执行器
idleMinutes 2
// 执行mvn 命令slave
yaml """
apiVersion: v1
kind: Pod
spec:
containers:
- name: maven
image: maven:3.8.2
command: ['sleep', 'infinity']
"""
}
}
stages {
// 阶段定义
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32

# 2.3 tools
主要用来安装工具使用,这里对应的是系统管理-->全局工具配置,建议通过图形化UI界面配置相关工具

# 2.4 options
完整使用示例,查看上面demo
options 配置提供了一些全局选项,用于自定义流水线的行为和特性,常见一些选项参数如下:
- **
timeout:**设置流水线最大运行时间,这样可以避免一些流水线任务因为耗时比较长导致一直运行从而影响其他job,当达到设定的时间,Jenkins 将自动中止流水线的执行。 buildDiscarder:用于配置构建丢弃策略,定义旧构建的保留规则。disableConcurrentBuilds:禁用了并发构建,防止同一流水线在同一时间并行运行多个实例。timestamps:在流水线输出中添加时间戳,方便追踪和调试。retry:在流水线失败时,自动重试,retry(3),表示重试3次。
# 2.5 triggers
triggers 是一个用于触发流水线运行的配置选项主要包含以下三种模式:
- cron:
cron触发器配置,设置Jenkins 将在指定的时间点触发流水线运行。 - scm:
scm触发器配置,设置Jenkins定时检测仓库代码,当有代码提交到源代码管理系统(如 Git)时,Jenkins 将检测到更改并触发流水线运行。 - upstream:
upstream触发器配置,关联其他流水线。这里允许您在一个流水线执行成功后自动触发另一个相关流水线的运行。
# 2.6 parameters
通过pipline配置的参数,需要先执行下构建,才会生效。
参数化构建参数,这个比较常用,支持的类型如下:
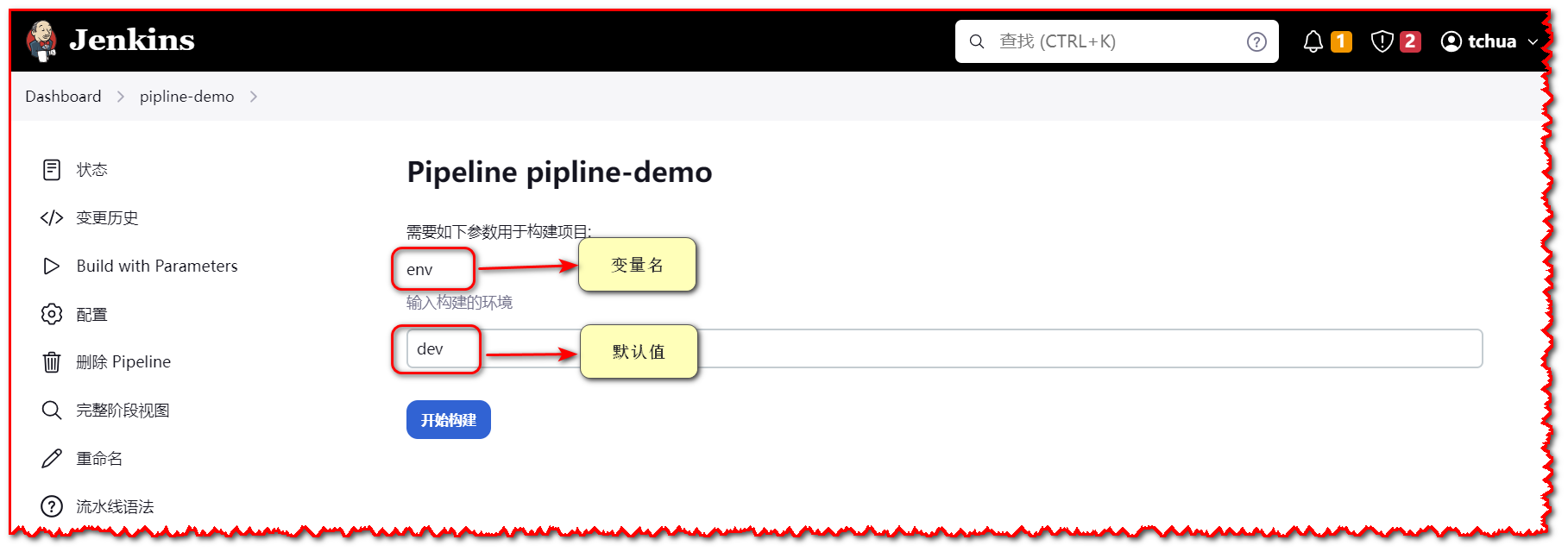
- string: 字符串类型,用于接收字符串值的参数。
parameters {
string(name: 'env', defaultValue: 'dev', description: '指定构建环境')
}
2
3
- text: 用于接收多行文本值的参数。
parameters {
text(name: 'PARAM_NAME', defaultValue: 'default value', description: 'Parameter description')
}
2
3
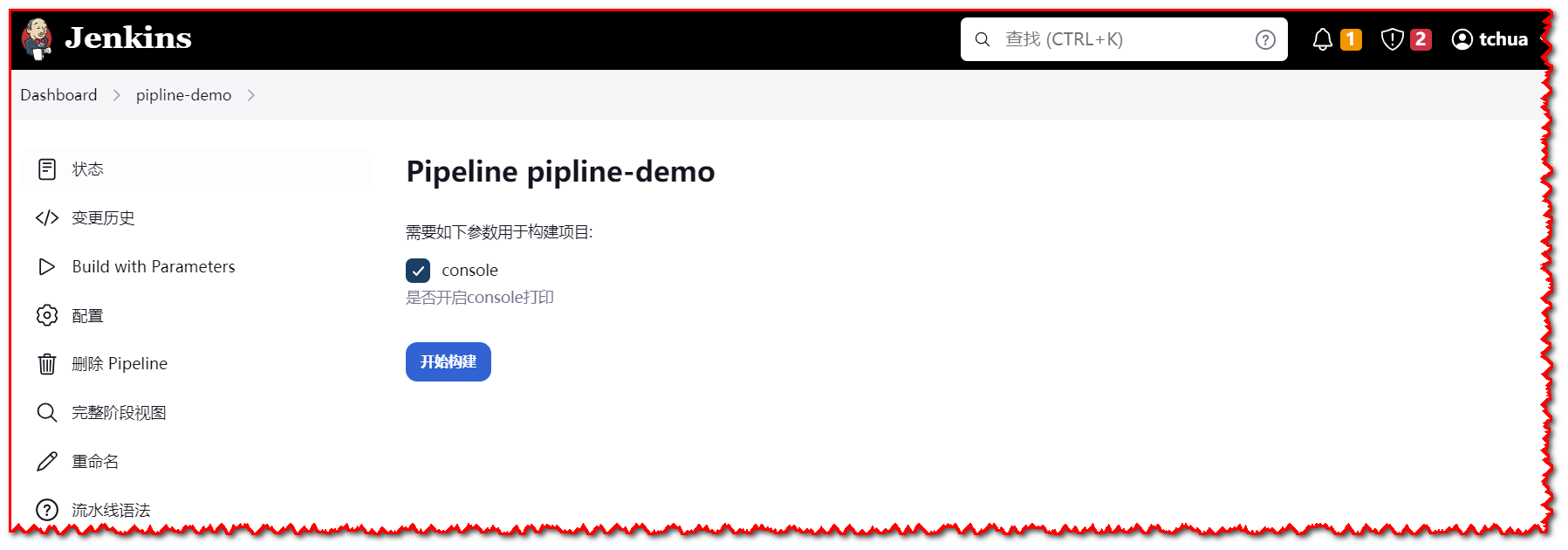
- boolean: 用于接收布尔值(true/false)的参数。
parameters {
booleanParam(name: 'console', defaultValue: true, description: '是否开启控制他打印')
}
2
3
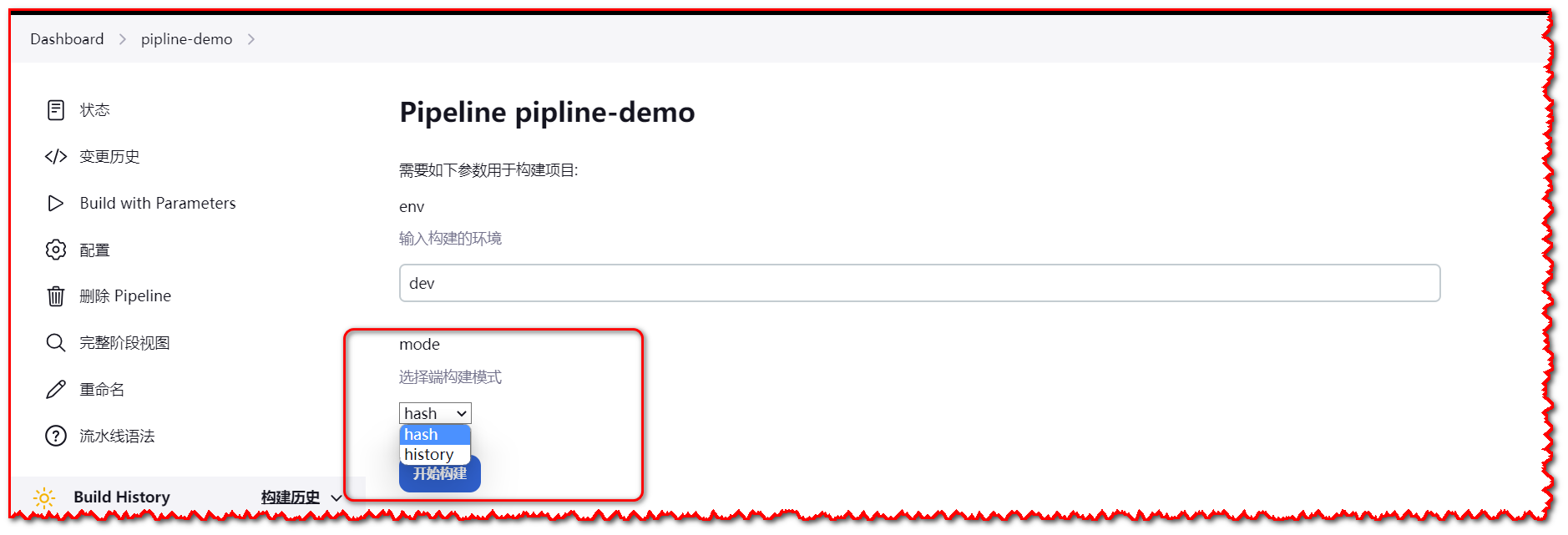
- **choice:**用于提供多个选项供用户选择的参数。
生产中用于构建环境、代码回滚等操作
parameters {
choice(name: 'mode', choices: ['hash', 'history'], description: '选择前端构建模式')
}
2
3
# 2.7 environment
用于定义环境变量的配置选项。环境变量是在流水线的执行期间可用的键值对,可以用于传递和访问各种配置和数据。
- 在流水线的
environment部分定义,可以在流水线任意部分调用
pipeline {
environment {
ENV_VAR = "value"
ANOTHER_VAR = "another value"
}
stages {
// 阶段定义
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
12
13
- 在阶段内部定义,该变量只能在该阶段内部使用
pipeline {
stages {
stage('Example') {
environment {
STAGE_VAR = "stage value"
}
steps {
// 在该阶段中可以使用 STAGE_VAR
}
}
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 在脚本步骤中定义:使用
withEnv定义的临时变量,仅在该步骤中使用。
pipeline {
stages {
stage('Example') {
steps {
script {
withEnv(["TEMP_VAR=value"]) {
// 仅在该步骤中可以使用 TEMP_VAR
}
}
}
}
}
// 后续操作定义
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.8 stages
stages 是用于定义流水线的阶段的部分。每个阶段可以包含一个或多个步骤,用于执行特定的任务或操作。stages 部分位于 pipeline 块中,它是一个顺序的阶段列表。每个阶段通过 stage 关键字定义,可以指定阶段的名称。
pipeline {
agent any
stages {
stage('Build') {
steps {
// 执行构建步骤
}
}
stage('Test') {
steps {
// 执行测试步骤
}
}
stage('Deploy') {
steps {
// 执行部署步骤
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2.9 stage
stage 是用于定义流水线中的不同阶段的关键字。每个 stage 定义了一个独立的阶段,表示流水线中的一个任务或操作。通过使用 stage,您可以将流水线拆分为多个逻辑阶段(steps),以实现更好的可读性、可维护性和可扩展性,stage阶段中主要包含以下内容:
# 2.9.1 steps
steps 是用于定义流水线中每个阶段中具体执行的步骤。步骤是流水线中的最小执行单元,用于执行特定的操作或任务。
- checkout: 从源代码管理系统(如Git)检出代码。
steps {
checkout([$class: 'GitSCM', branches: [[name: 'master']], userRemoteConfigs: [[url: 'https://github.com/example/repo.git']]])
}
2
3
- **sh:**在步骤中直接执行shell命令。
steps {
sh 'npm install'
sh 'npm test'
}
2
3
4
- script: 执行任意的Groovy脚本,允许执行自定义的逻辑和操作。
pipeline {
agent any
stages {
stage('Script Example') {
steps {
script {
// 在这里编写自定义的Groovy脚本
def name = 'tchua'
def age = 30
println "Hello, ${name}!"
println "You are ${age} years old."
// 可以调用其他的模块操作
sh 'echo "This is a shell command"'
git 'https://github.com/example/repo.git'
}
}
}
// 其他阶段
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2.9.2 when
when 参数用于根据条件来控制流水线的执行。
stage('Deploy') {
when {
branch 'master'
environment name: 'DEPLOY_TO_PROD', value: 'true'
}
// 部署步骤定义
}
2
3
4
5
6
7
when 支持以下条件:
- branch: 基于当前的
SCM分支名称匹配条件.
stage('Build') {
when {
branch 'master' // 当分支名称是 master 时执行
}
// 步骤定义
}
2
3
4
5
6
- changeset: 基于
SCM中的更改集匹配条件。
stage('Build') {
when {
changeset "**/*.java" // 当有 Java 文件更改时执行
}
// 步骤定义
}
2
3
4
5
6
- expression: 基于自定义 Groovy 表达式的匹配条件。
通常我们使用选项参数时,会使用到该选项,当然也可以自定义表达式
pipeline {
agent any
parameters {
choice(name: 'mode', choices: ['hash', 'history'], description: '选择端构建模式')
}
stages {
stage('deploy(发布/CD)') {
when {
expression {
return params.mode == 'hash' // 当构建参数 BUILD_TYPE 的值是 'Release' 时执行
}
}
steps {
echo '当mode变量为hash时,我才执行'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- environment: 基于环境变量的匹配条件。
stage('Build') {
when {
environment name: 'BUILD_TYPE', value: 'Release' // 当环境变量 BUILD_TYPE 的值是 'Release' 时执行
}
// 步骤定义
}
2
3
4
5
6
- not: 对其他条件的逻辑取反。
stage('Build') {
when {
not {
branch 'feature/*' // 当分支名称不匹配 'feature/*' 时执行
}
}
// 步骤定义
}
2
3
4
5
6
7
8
- allOf: 所有条件都必须满足时才执行。
stage('Build') {
when {
allOf {
branch 'master'
environment name: 'BUILD_TYPE', value: 'Release'
}
}
// 步骤定义
}
2
3
4
5
6
7
8
9
- anyOf: 至少有一个条件满足时执行。
stage('Build') {
when {
anyOf {
branch 'master'
environment name: 'BUILD_TYPE', value: 'Release'
}
}
// 步骤定义
}
2
3
4
5
6
7
8
9
# 2.9.3 timeout
设置该阶段设置超时时间,如果超过指定时间,则中断该阶段的执行。
stage('Build') {
timeout(time: 30, unit: 'MINUTES') {
// 步骤定义
}
}
2
3
4
5
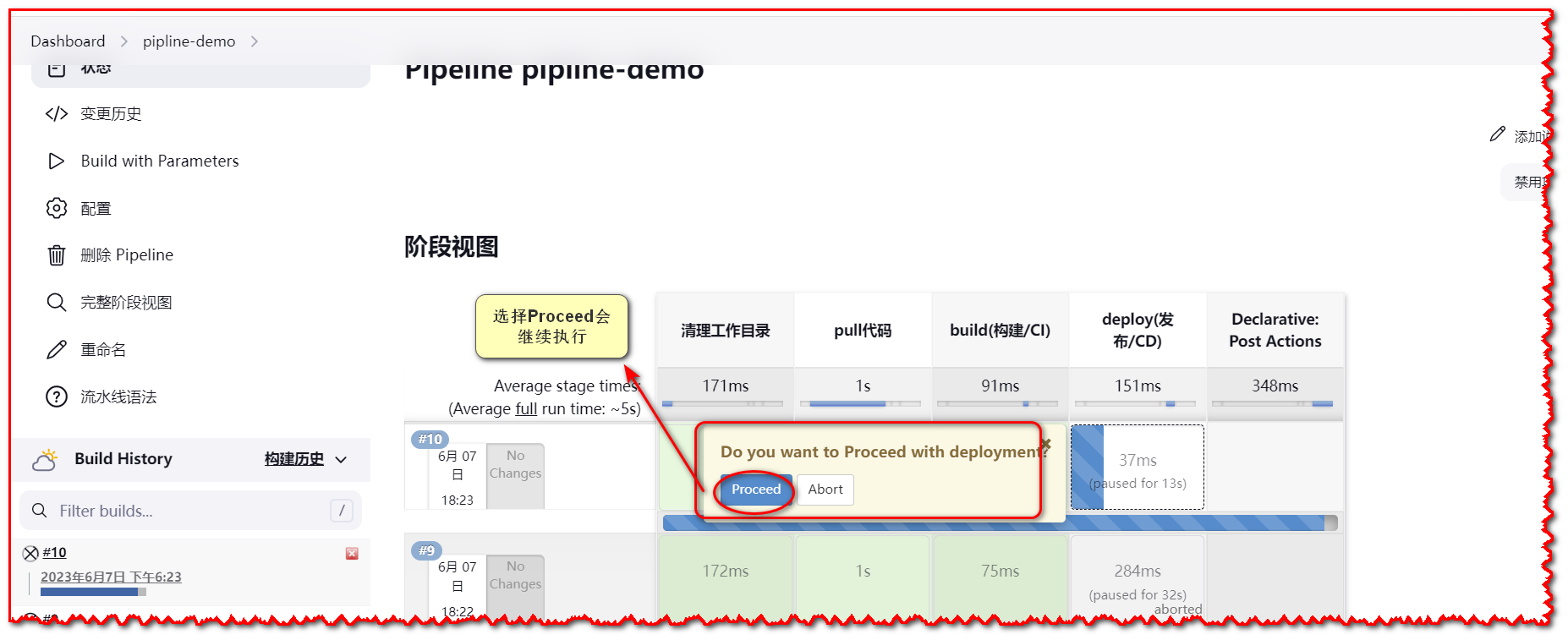
# 2.9.4 input
在该阶段中暂停流水线并等待用户输入。用户可以在输入提示中提供反馈后继续执行。
stage('Deploy') {
input {
message 'Do you want to process with deployment?'
ok 'Proceed'
}
// 部署步骤定义
}
2
3
4
5
6
7
# 2.9.5 parallel
允许在当前阶段中并行执行多个步骤。可以在 parallel 块中定义多个步骤,并将它们同时运行,比如,我们可以通知试下代码构建,和代码检测步骤,或者把构建产物同时发布至不同环境。
stage('deployment') {
parallel {
stage('dev环境部署') {
// 步骤定义
}
stage('test环境部署') {
// 步骤定义
}
}
}
2
3
4
5
6
7
8
9
10
# 2.10 post
定义在Pipeline执行完成后执行的步骤,Pipeline的顶层定义,并且只能定义一次
pipeline {
agent any
stages {
// 阶段定义
}
post {
success {
echo '构建成功!'
// 在构建成功时执行的步骤
}
failure {
echo '构建失败!'
// 在构建失败时执行的步骤
}
aborted {
echo '构建中断!'
// 在构建中断时执行的步骤
}
unstable {
echo '构建不稳定!'
// 在构建不稳定时执行的步骤
}
always {
echo '无论构建结果如何,总是执行!'
// 无论构建结果如何,总是执行的步骤
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 2.11总结
以上是对pipline常用的一些属性和功能介绍,我们在实际使用的时候,需要灵活运用,上面每一个部分都还可以执行很多属性,来对job任务进行定义,因此,熟悉这些只是一个开始,想真正的玩明白流水线相关,还是需要我们自己去结合业务去实践。
后面我也会根据经常遇到的场景分解去讲解在实际生产中的使用,当然,前提是你对上面的基于已经掌握。