 kafka二进制模式集群部署
kafka二进制模式集群部署
# 一、背景介绍
关于kafka简单介绍可以查看这边文章Docker部署kafka集群 (opens new window),这里介绍下传统方式二进制部署以及kafka3.x版本使用zookeeper和内置的Kraft进行集群部署,关于集群机器规划如下:
| 主机 | IP | 端口 | 角色 |
|---|---|---|---|
| kafka-zk-01 | 172.16.10.79 | 9092,9093,2181 | broker,zookeeper |
| kafka-zk-02 | 172.16.10.80 | 9092,9093,2181 | broker,zookeeper |
| kafka-zk-03 | 172.16.10.81 | 9092,9093,2181 | broker,zookeeper |
# 二、集群部署
# 2.1 jdk配置
jdk版本使用的是
jdk-11.0.8
# 解压
tar -xf jdk-11.0.8_linux-x64_bin.tar.gz -C /usr/local/
# 环境变量配置
vim /etc/profile
#jdk11
JAVA_HOME=/usr/local/jdk-11.0.8
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
# 加载环境配置
[root@kafka-zk-03 ~]# source /etc/profile
[root@kafka-zk-03 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.2 kafka下载
更多下载: https://dlcdn.apache.org/kafka
wget https://dlcdn.apache.org/kafka/3.4.1/kafka_2.12-3.4.1.tgz
# 2.3 解压
tar -xf kafka_2.12-3.4.1.tgz -C /opt/
# 2.4 Kafka with KRaft模式
在kafka3.x版别中,运用Kraft协议代替zookeeper进行集群的Controller选举,所以启动配置文件有区别于kafka2.x,配置文件在config/kraft目录下,这与kafka2.x版别依赖zookeeper的配置文件是不同的
# 2.4.1 配置文件修改
配置路径
/opt/kafka_2.12-3.4.1/config/kraft/server.properties,注意每个主机组配置参数的唯一性。
# vim /opt/kafka_2.12-3.4.1/config/kraft/server.properties
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@172.16.10.79:9093,2@172.16.10.80:9093,3@172.16.10.81:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://172.16.10.79:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.dirs=/opt/kafka/data
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
参数解释
process.roles:设置Kafka Broker的角色,这里配置为同时充当Broker(kafka实例)和Controller(类似于zk),也可以只配置一个角色,需要注意是controller的数量必须为奇数个,与zk原理一致。node.id:指定Kafka Broker节点的ID,此处设置为1,类似kafka2中的broker.id。controller.quorum.voters:列出Kafka Controller的投票者配置。它定义了一组Controller节点,其中包括它们各自的ID和网络地址。listeners:设置Kafka Broker监听的网络端口。在此配置中,它监听9092端口的PLAINTEXT协议和9093端口的CONTROLLER协议。inter.broker.listener.name:设置用于Broker之间通信的监听器名称,此处设置为PLAINTEXT。advertised.listeners:指定向客户端广播的网络地址。客户端将使用该地址与Broker进行通信。controller.listener.names:定义Kafka Controller用于通信的监听器名称,此处设置为CONTROLLER。listener.security.protocol.map:将监听器名称映射到它们对应的安全协议,从而实现客户端与Broker之间的安全通信。在此配置中,CONTROLLER被映射为PLAINTEXT。num.network.threads:设置Kafka Broker用于处理网络请求的线程数。num.io.threads:设置Kafka Broker用于执行I/O操作的线程数。socket.send.buffer.bytes:设置套接字发送操作的缓冲区大小。socket.receive.buffer.bytes:设置套接字接收操作的缓冲区大小。socket.request.max.bytes:设置Broker可以处理的最大请求大小。num.partitions:设置新主题的默认分区数。num.recovery.threads.per.data.dir:设置Broker用于日志恢复的每个数据目录的线程数。offsets.topic.replication.factor:设置存储偏移量的内部Kafka主题的复制因子。transaction.state.log.replication.factor:设置事务状态日志的复制因子。transaction.state.log.min.isr:设置事务状态日志所需的最小同步副本数。log.retention.hours:设置日志段保留的最大时间(以小时为单位)。log.segment.bytes:设置单个日志段的大小(以字节为单位)。log.retention.check.interval.ms:设置检查日志保留的间隔时间(以毫秒为单位)。log.dirs:设置Kafka Broker存储日志数据的目录。
# 2.4.2 生成集群 UUID
这里我们可以使用kafka自带的工具
# 生成集群UUID(存储目录唯一ID) 随便一台主机即可
[root@kafka-zk-01 kafka_2.12-3.4.1]# bin/kafka-storage.sh random-uuid
uVCxlrGwQ3qasq-I5VKuoA
# 使用上面UUID格式化 三个节点上数据存储目录
## 三台节点都需要执行 主要配置文件不要指定错了 执行之后会在定义的数据目录下 生成meta.properties元信息文件
bin/kafka-storage.sh format -t uVCxlrGwQ3qasq-I5VKuoA -c config/kraft/server.properties
2
3
4
5
6
# 2.4.3 启动集群
- 节点1:kafka-zk-01
[root@kafka-zk-01 kafka_2.12-3.4.1]# bin/kafka-server-start.sh -daemon config/kraft/server.properties
- 节点2: kafka-zk-02
[root@kafka-zk-02 kafka_2.12-3.4.1]# bin/kafka-server-start.sh -daemon config/kraft/server.properties
- 节点3: kafka-zk-03
[root@kafka-zk-03 kafka_2.12-3.4.1]# bin/kafka-server-start.sh -daemon config/kraft/server.properties
# 2.4.4 集群验证
启动之前,如果没有报错日志,我们可以通过创建一个topic来验证下集群是否正常启动
# 创建topic my-test
bin/kafka-topics.sh --create --topic my-test --bootstrap-server localhost:9092
# 显示主题信息
bin/kafka-topics.sh --describe --topic my-test --bootstrap-server localhost:9092
2
3
4

# 2.5 Kafka with ZooKeeper模式
# 2.5.1 zookeeper集群部署
kafka3.x版本虽说可以遗弃zookeeper独立部署,但是也还是支持依赖zookeeper的模式进行部署,这里部署之前就需要先把zookeeper集群启动,关于zookeeper集群可以使用kafka自带的命令启动,也可以使用外部的已经部署好的或者独立部署,这里直接使用前面部署过的Docker部署zookeeper3.6集群 (opens new window)
# 2.5.2 配置修改
配置文件路径:
/opt/kafka_2.12-3.4.1/config/server.properties
broker.id=0
listeners=PLAINTEXT://172.16.10.79:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=172.16.10.79:2181,172.16.10.80:2181,172.16.10.81:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
注释
# 为Kafka broker设置唯一的ID。在Kafka集群中,每个broker必须有一个唯一的ID。
broker.id=0
# 设置broker的监听地址配置,一般为主机IP,这样只会监听指定的IP,如果有多个IP,则可以默认不写,这样会监听0.0.0.0
listeners=PLAINTEXT://172.16.10.79:9092
# 用于处理网络请求的线程数
num.network.threads=3
# 用于处理磁盘IO的线程数
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# Kafka将存储其日志数据的目录
log.dirs=/tmp/kafka-logs
# 主题默认分区数
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 日志段保留的时间周期(超过此时间的日志将被删除)
log.retention.hours=168
log.retention.check.interval.ms=300000
# 用于Kafka连接到ZooKeeper集合的ZooKeeper连接字符串。
zookeeper.connect=172.16.10.79:2181,172.16.10.80:2181,172.16.10.81:2181
zookeeper.connection.timeout.ms=18000
# 新的消费者加入消费者组后,初始消费者组重新平衡的延迟时间(以毫秒为单位)。
group.initial.rebalance.delay.ms=0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 2.4.3 集群启动
- 节点1: kafka-zk-01(172.16.10.79)
bin/kafka-server-start.sh -daemon config/server.properties
- 节点2: kafka-zk-02(172.16.10.80)
bin/kafka-server-start.sh -daemon config/server.properties
- 节点3: kafka-zk-03(172.16.10.81)
bin/kafka-server-start.sh -daemon config/server.properties
# 2.4.4 集群验证
这里随便一台主机创建topic,然后查看下主题的分片分配
[root@kafka-zk-01 kafka_2.12-3.4.1]# bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server 172.16.10.79:9092
Created topic quickstart-events.
[root@kafka-zk-01 kafka_2.12-3.4.1]# bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 172.16.10.79:9092
Topic: quickstart-events TopicId: pG6GGkWjRHCbG0eawvhDHA PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: quickstart-events Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: quickstart-events Partition: 2 Leader: 1 Replicas: 1 Isr: 1
2
3
4
5
6
7
# 三、kafka图形化
kafka的图形化管理可以部署kafka-manager (opens new window),目前项目已经改名为CMAK (opens new window)。
# 3.1 下载安装包
# 下载
wget https://github.com/yahoo/CMAK/releases/download/3.0.0.6/cmak-3.0.0.6.zip
# 解压
unzip cmak-3.0.0.6.zip
2
3
4
# 3.2 配置修改
配置文件路径:
cmak-3.0.0.6/config/application.conf
# 修改此参数,指定zk地址即可
cmak.zkhosts="172.16.10.79:2181,172.16.10.80:2181,172.16.10.81:2181"
2
# 3.3 启动
./bin/cmak -Dconfig.file=conf/application.conf
启动之后,会监听指本机9000端口,然后我们直接访问:http://ip:9000

# 3.4 添加集群
- 添加新建集群
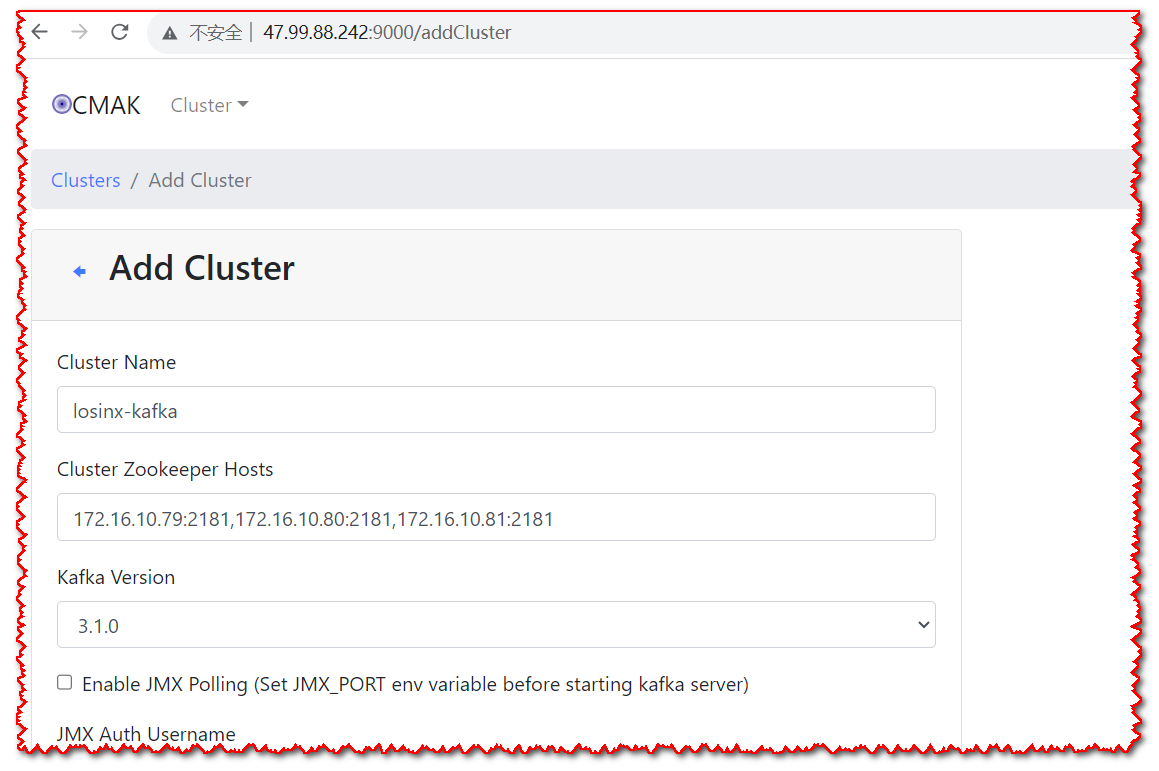
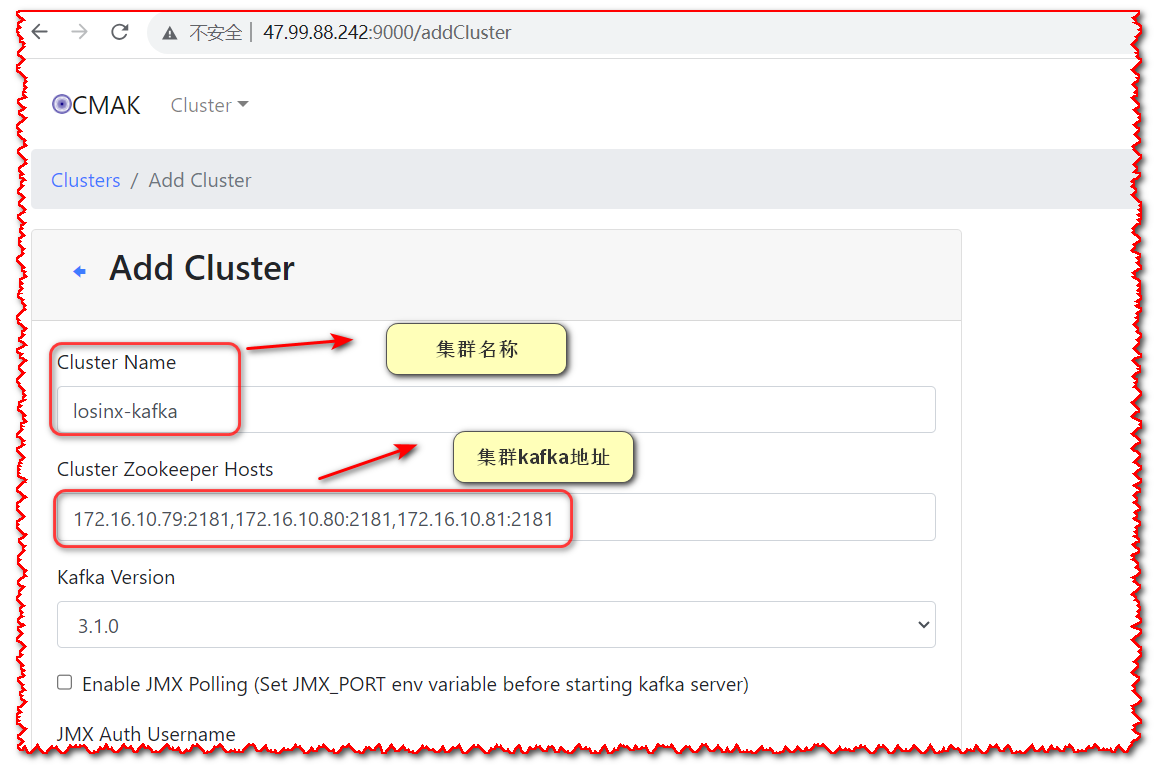
- 配置集群参数
参数配置好后,拉到最下面点击保存即可,如果有报错,根据提示填写相关参数即可

# 3.5 查看集群信息
集群添加成功后,我们可以在顶部导航,看到相关菜单,直接点击查看相关信息
# 3.5.1 查看集群节点

# 3.5.2 查看topic信息

# 3.5.3 查看主题相信信息


# 3.6 创建主题


 四、分区副本数
四、分区副本数
# 4.1 主题分区及副本关系
- 主题(Topic):
- 主题是Kafka消息的逻辑分类,用于组织和归类消息。每个主题可以看作是一个消息流,生产者将消息发布到特定的主题,而消费者则从主题订阅消息。
- 主题的名字是一个字符串,用于标识不同的消息流。在创建主题时,可以指定主题的分区数和复制因子。
- 分区(Partition):
- 主题可以被分成多个分区,每个分区是主题的一个子集,并且是消息在Kafka中存储和传输的基本单位。
- 分区是Kafka实现高吞吐量和横向扩展的关键。不同的分区可以并行处理消息,从而实现数据的并行处理和负载均衡。
- 每个分区在Kafka集群中的不同broker上都有多个副本。
- 可以通过配置文件指定默认分区(num.partitions=n),也可以在创建时指定(--partitions)
- 副本(Replica):
- 副本是对一个分区的复制,它用于实现数据的冗余和高可用性。
- 每个分区通常有多个副本,这些副本分布在Kafka集群中的不同broker上。其中一个副本被选举为“Leader”,负责处理消息的读写请求;其他副本是“Follower”,只负责从Leader同步消息并保持与Leader的数据一致性。
- 副本的数量由主题的复制因子决定。如果复制因子为N,则每个分区将有N个副本,其中N-1个是Follower副本,1个是Leader副本。
# 4.2 关于查看主题参数解读
- 创建主题
创建主题
losinx-wms,分区数为3,每个分区副本数为3
bin/kafka-topics.sh --create --bootstrap-server 172.16.10.79:9092 --replication-factor 3 --partitions 3 --topic losinx-wms
- 主题
--describe显示结果解释
bin/kafka-topics.sh --describe --bootstrap-server 172.16.10.79:9092 --topic losinx-wms
Topic: losinx-wms TopicId: UguHPhEUSGG15EnvQobI2g PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: losinx-wms Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: losinx-wms Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: losinx-wms Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
2
3
4
5

信息解读
- ① :指主题分区的一个总结,主题名losinx-wms,三个分区,每个分区三个副本
- ②:三个分区的副本分配信息
- leader 是在给出的所有
partitons中负责读写的节点,每个节点都有可能成为leader。 - replicas 显示给定partiton所有副本所存储节点的节点列表,不管该节点是否是leader或者是否存活。
- isr 副本都已同步的的节点集合,这个集合中的所有节点都是存活状态,并且跟leader同步。
- leader 是在给出的所有